SQL優(yōu)化方法論與實(shí)戰(zhàn)
當(dāng)前位置:點(diǎn)晴教程→知識(shí)管理交流
→『 技術(shù)文檔交流 』
前言這兩天在團(tuán)隊(duì)內(nèi)部分享了一篇 《SQL優(yōu)化方法論與實(shí)戰(zhàn)》,在此也簡(jiǎn)單整理成文字稿分享給各位。 正文首先為什么要進(jìn)行優(yōu)化?說(shuō)得直白點(diǎn),無(wú)外乎是為了在現(xiàn)有資源情況下,不付出額外的成本,提升體驗(yàn),又曰——降本增效。
那么數(shù)據(jù)庫(kù)作為日常背鍋選手,有哪些可以衡量性能的指標(biāo)呢?我大致列了以下幾項(xiàng):
比如應(yīng)用告警報(bào)錯(cuò)閾值是 10 ms,如果某個(gè)時(shí)間段報(bào)錯(cuò)數(shù)量急劇增加,這個(gè)時(shí)候可能數(shù)據(jù)庫(kù)的狀態(tài)就不太正常了,其次數(shù)據(jù)庫(kù)的緩存命中率其實(shí)也可以從側(cè)面反映出數(shù)據(jù)庫(kù)的狀態(tài),大量 cache miss,性能注定好不到哪里去。
而延遲作為集中式數(shù)據(jù)庫(kù)的關(guān)鍵性黃金指標(biāo),延遲至關(guān)重要,假如我在某個(gè)商品界面上發(fā)起下單請(qǐng)求,等了許久才彈出一個(gè)付款界面,那么我會(huì)轉(zhuǎn)身就走,購(gòu)買欲望瞬間降至冰點(diǎn),延遲直接關(guān)系到用戶體驗(yàn)。 那么作為 DBA 的我們,對(duì)于延遲也要有個(gè)大概的"尺度",比如稍微差一點(diǎn)的盤,尋道時(shí)間在 3 ~ 10 ms 左右,毫秒級(jí)別,L1 / L2 CPU 緩存則在納秒級(jí)別,內(nèi)存訪問的話則是在 100 納秒的級(jí)別。那如果現(xiàn)在有個(gè) redis ,延遲為 100 ms,你說(shuō)慢不慢?當(dāng)然是慢的摳腳。
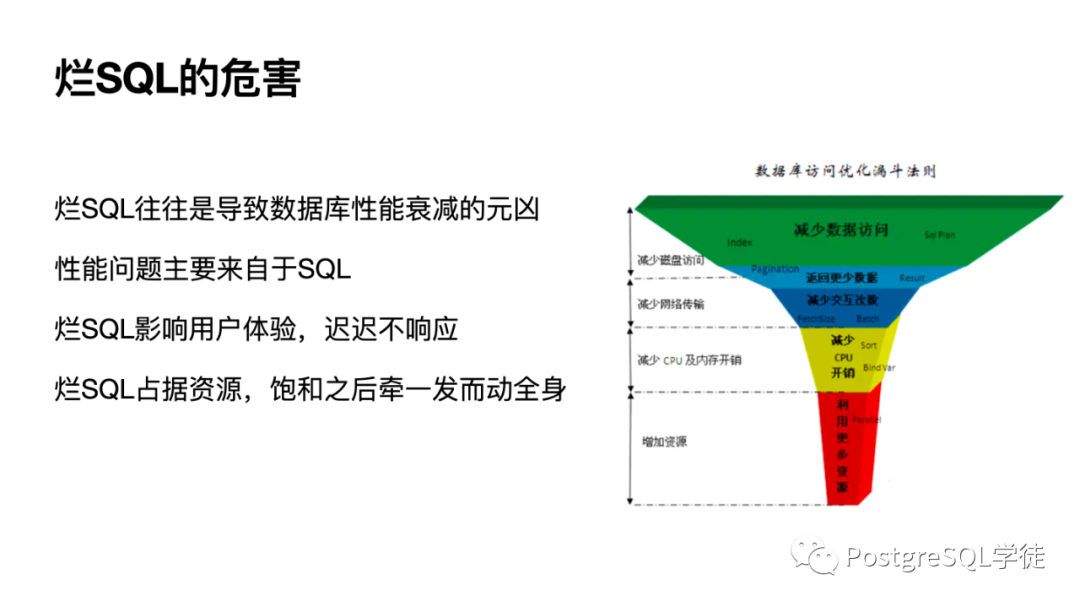
爛 SQL 的危害如果真要一一列舉出來(lái),可能到天黑都說(shuō)不完,爛 SQL 往往是導(dǎo)致數(shù)據(jù)庫(kù)性能衰減的元兇,性能問題源于 SQL,之外可能源于并發(fā) (居多) 或數(shù)據(jù)庫(kù)和操作系統(tǒng)自身維護(hù)性操作 (vacuum / freeze) 等等。
因此獲取現(xiàn)場(chǎng)就變得尤為重要,但 PostgreSQL 一直惱于沒有原生好用成熟的 AWR 工具,所以得借助一些第三方工具,此處我也簡(jiǎn)單整理了一下常用工具和插件,比如類似于 cursor sharing 的 pg_shared_plans,執(zhí)行計(jì)劃固化 sr_plan / pg_plan_guarentee 等,pg_stat_statements 肯定得裝上,基于 pg_stat_statements 實(shí)現(xiàn)丐版 AWR 也可以,關(guān)于這點(diǎn)可以抄作業(yè) 👉🏻 Using pg_stat_statements to Optimize Queries
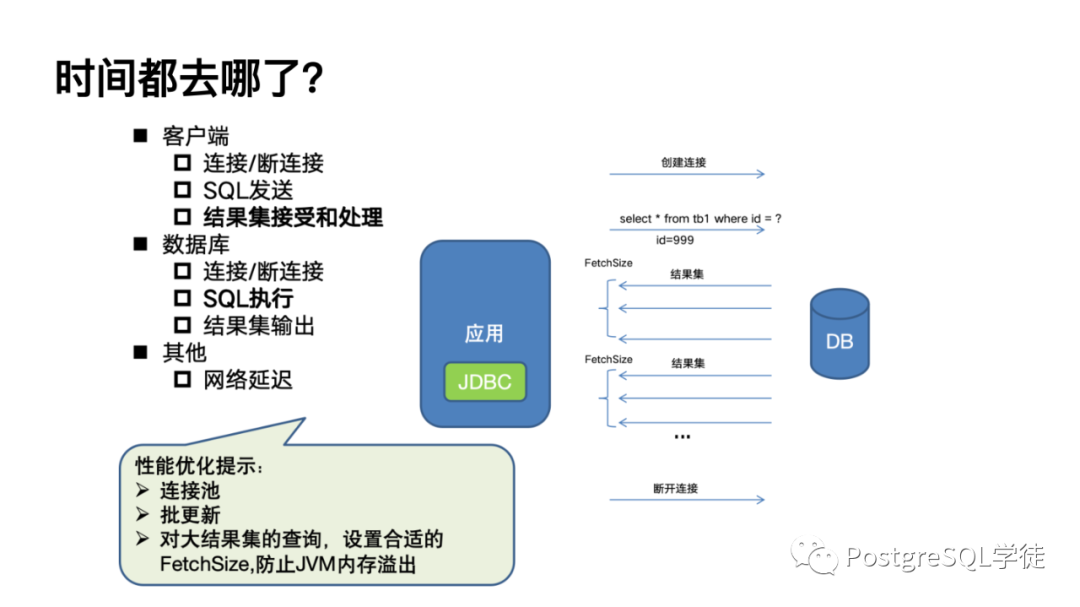
SQL 從客戶端發(fā)起,到數(shù)據(jù)庫(kù)執(zhí)行,再到接收,中間的每一環(huán)節(jié)都至關(guān)重要,比如網(wǎng)絡(luò)帶寬直接就決定了數(shù)據(jù)庫(kù)的吞吐量,這里要提一句的是,和 fetchsize 類似的是 FETCH_COUNT,也是為了防止客戶端 OOM,當(dāng)客戶端向數(shù)據(jù)庫(kù)發(fā)送請(qǐng)求時(shí),如果結(jié)果集很大,可能會(huì)把客戶端的內(nèi)存打爆,悠著點(diǎn)兒。
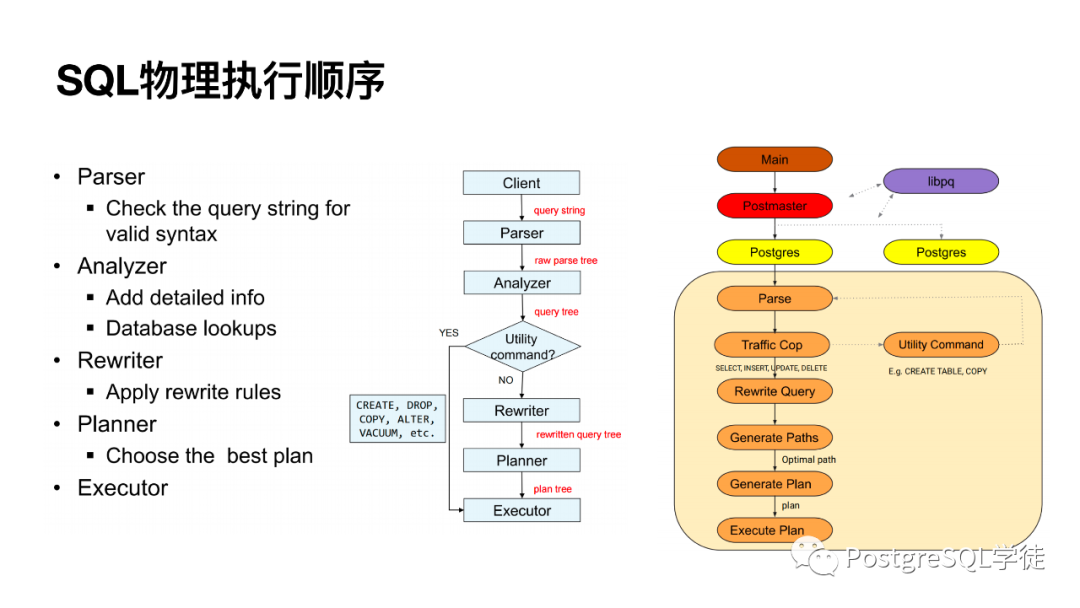
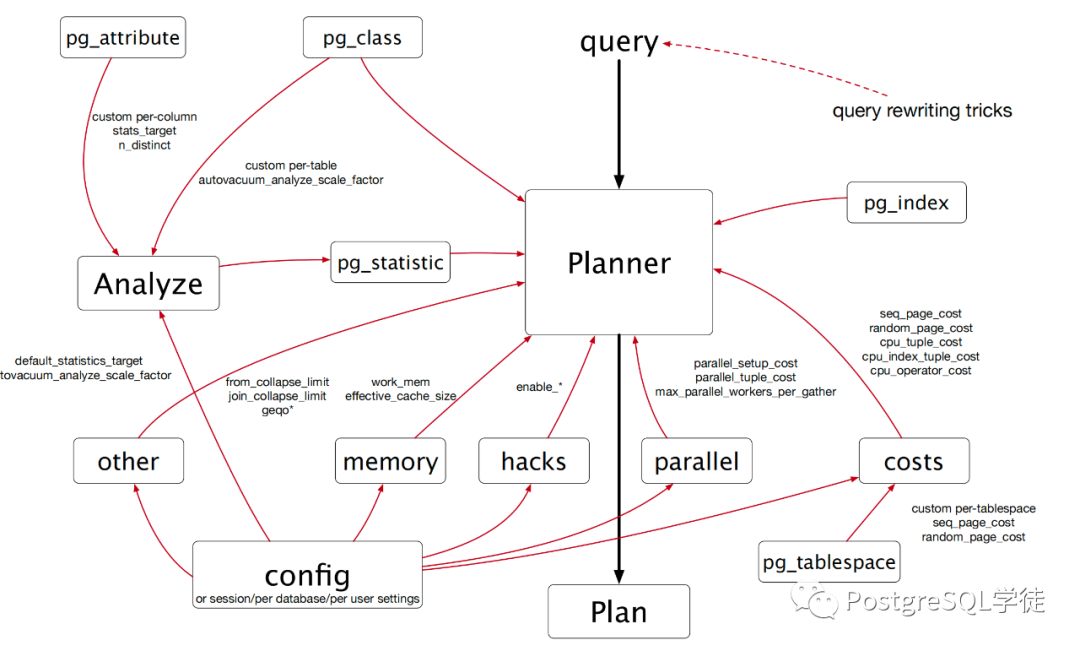
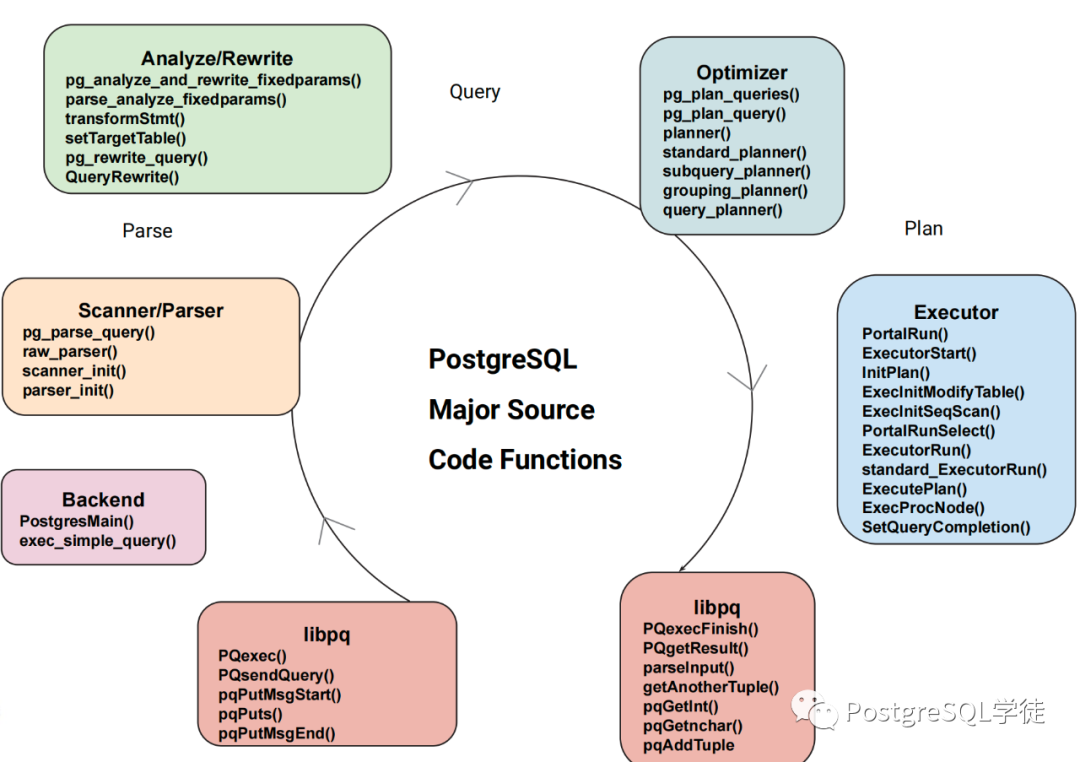
SQL 的邏輯順序不多說(shuō)了,關(guān)于物理執(zhí)行順序需要說(shuō)明一下。 當(dāng)一條查詢進(jìn)來(lái)之后,會(huì)經(jīng)過Parser → Analyzer → Rewriter → Planner → executor 這一系列步驟,生成各種各樣的"樹"。若是 DDL 語(yǔ)句,無(wú)需進(jìn)行優(yōu)化,到 utility 模塊處理,對(duì)于 DML 則需要按照完整的流程。(最近我正在看 "Journey of a DML query",后續(xù)也會(huì)分享給各位)。 對(duì)于數(shù)據(jù)庫(kù)來(lái)說(shuō),傳入的 SQL 語(yǔ)句不過是一串"文本",PostgreSQL 并不知曉也不理解這一串文本是什么意思,因此我們需要告訴數(shù)據(jù)庫(kù)該如何理解這一串文本,之后 SQL 語(yǔ)句就會(huì)被轉(zhuǎn)化為內(nèi)部結(jié)構(gòu),即語(yǔ)法解析樹,再經(jīng)過優(yōu)化的處理,最終轉(zhuǎn)化為執(zhí)行器可以高效執(zhí)行的計(jì)劃樹。 而優(yōu)化器作為數(shù)據(jù)庫(kù)的大腦,優(yōu)化器的好壞直接決定了一個(gè)數(shù)據(jù)庫(kù)的"上限",決定了一個(gè)數(shù)據(jù)庫(kù)面對(duì)復(fù)雜語(yǔ)句的處理能力。說(shuō)白了,邏輯優(yōu)化就是盡量對(duì)查詢進(jìn)行等價(jià)或者推倒變換,以達(dá)到更有效率的執(zhí)行計(jì)劃。因?yàn)?SQL 是聲明式語(yǔ)言,我們只是指定了需要返回什么結(jié)果,而沒有指定它該怎么做。 在此也貼一個(gè)關(guān)于優(yōu)化器涉及到的相關(guān)參數(shù)和系統(tǒng)表,以及核心代碼流程,之前有位讀者問過我這塊:
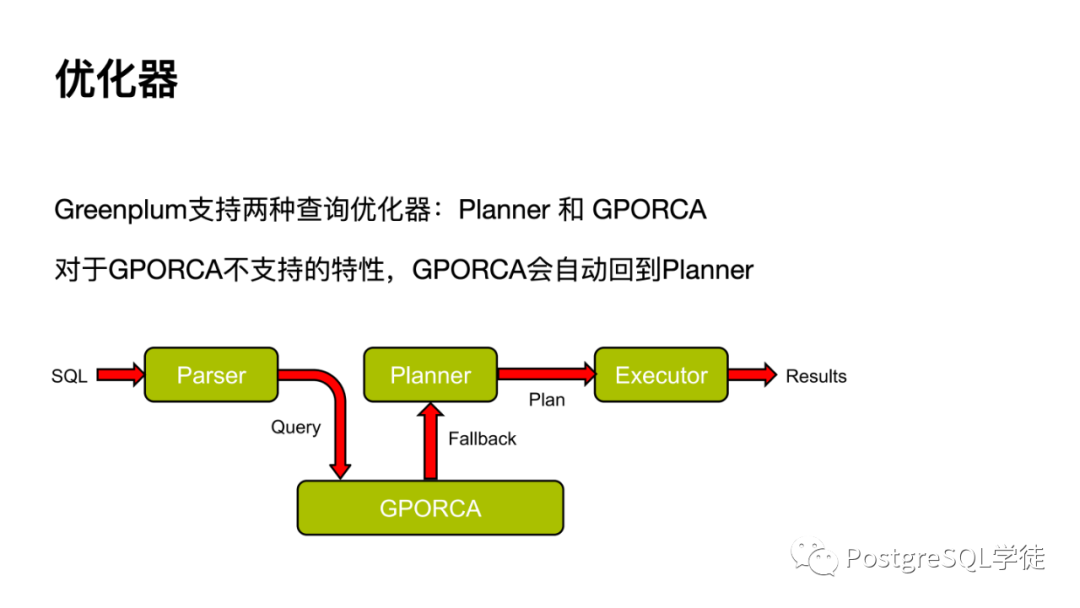
對(duì)于 Greenplum 來(lái)說(shuō),他既支持傳統(tǒng) PostgreSQL 優(yōu)化器,也有 ORCA。對(duì)于 GPORCA 不支持的特性,GPORCA 會(huì)自動(dòng)回到 Planner。
其中 PostgreSQL 優(yōu)化器采用了兩種方法:自底向上使用的是動(dòng)態(tài)規(guī)劃,隨機(jī)方法使用的是遺傳算法,由geqo_threshold 參數(shù)控制何時(shí)使用遺傳算法,默認(rèn)是 12。 對(duì)于 OUTER JOIN 來(lái)說(shuō),JOIN 順序是固定的,所以路徑數(shù)量相對(duì)較少 (只需要考慮不同 JOIN 算法組成的路徑);然而對(duì)于 INNER JOIN 來(lái)說(shuō),表之間的 JOIN 順序是可以不同的,這樣就可以由不同的 JOIN 組合、不同的 JOIN 順序組成非常多的不同路徑。如
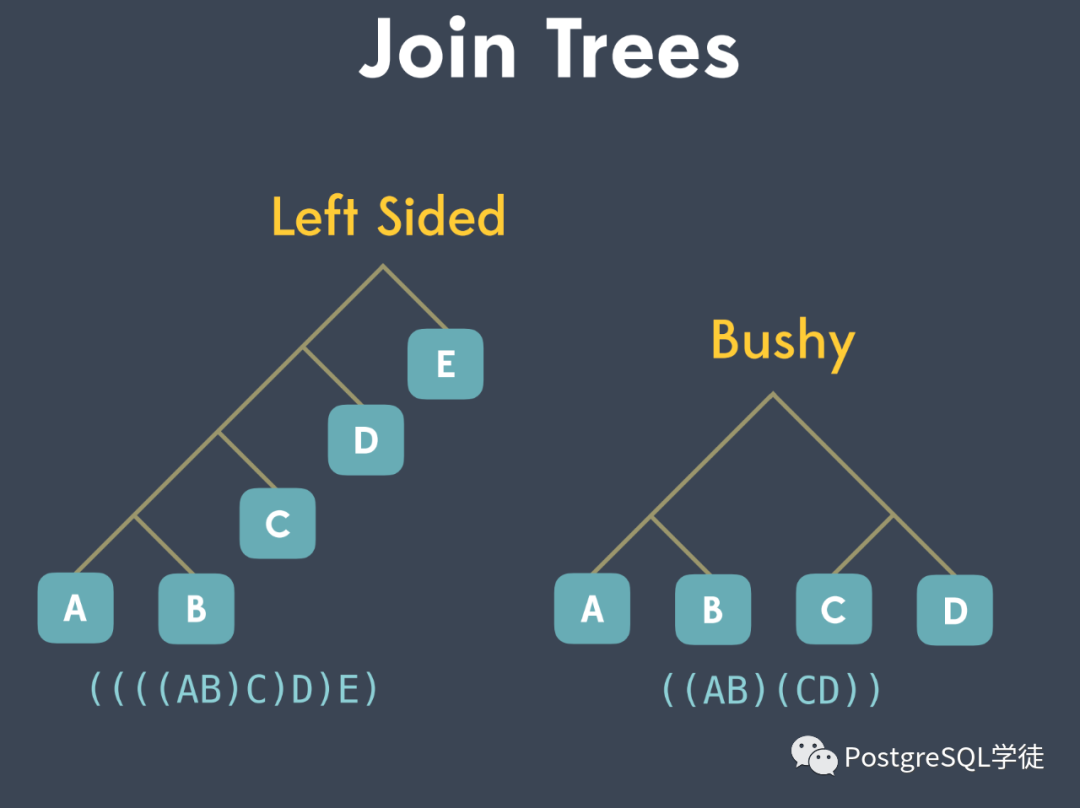
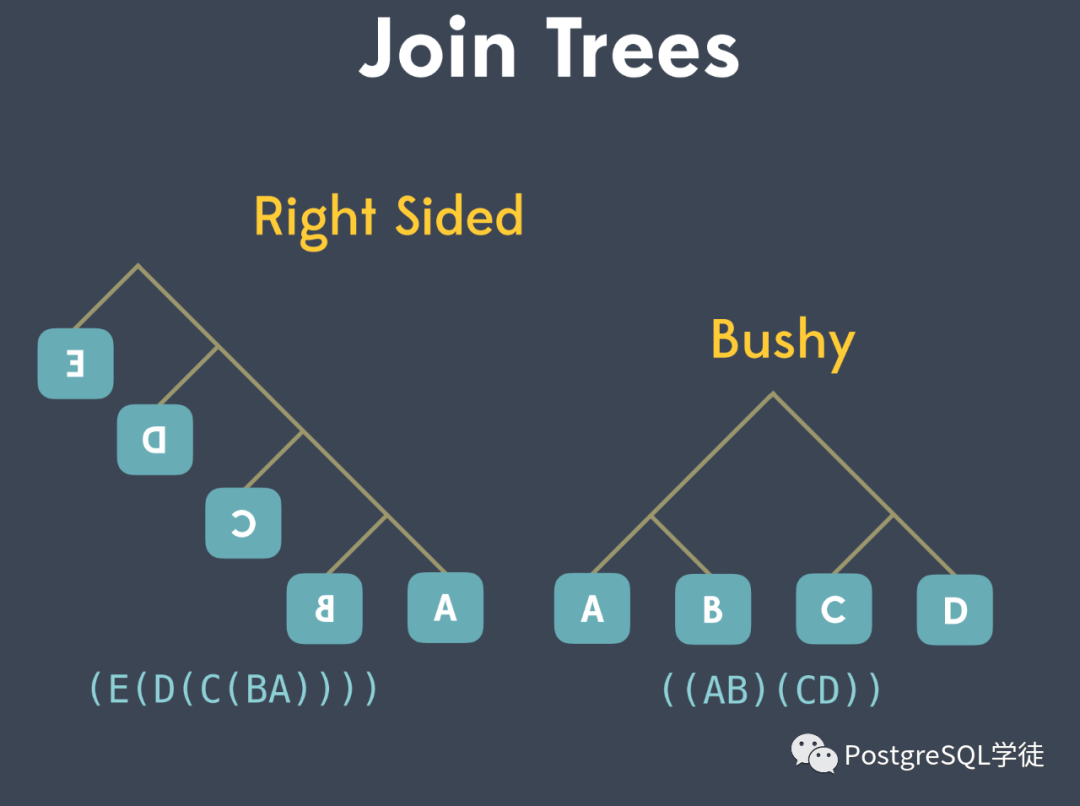
等等。多表間的連接順序表示了查詢計(jì)劃樹的基本形態(tài)。一棵樹就是一種查詢路徑,SQL 的語(yǔ)義可以由多棵這樣的樹表達(dá),從中選擇花費(fèi)最少的樹,就是最優(yōu)查詢計(jì)劃形成的過程。一棵樹包括左深連接樹、右深連接樹、緊密樹。PostgreSQL 優(yōu)化器主要考慮將執(zhí)行計(jì)劃樹生成以下三種形式,包括左深樹、右深樹和緊密型樹。不同的連接順序,會(huì)生成不同大小的中間關(guān)系,對(duì)應(yīng) CPU 和 IO 消耗不同。 PostgreSQL 中會(huì)嘗試多種連接方式存放到 "path" 上,以找出花費(fèi)最小的路徑。
試想一下,如果A ⨝ B ⨝ C ⨝ D,那么有 N! ✕ (N-1)! 這么多種可能的計(jì)劃 (ABCD, ABDC, ADBC, DABC ...)。人們針對(duì)樹的形成及其花費(fèi)代價(jià)最少的,提出了諸多算法。樹形成過程有以下兩種策略:
在數(shù)據(jù)庫(kù)實(shí)現(xiàn)中,多數(shù)數(shù)據(jù)庫(kù)采取了自底向上的策略。就 PostgreSQL 而言,查詢優(yōu)化可以大體分為四個(gè)步驟:
如果看到這樣類似的關(guān)鍵字,則代表是 ORCA 優(yōu)化器,其是基于自頂向下的查詢優(yōu)化器,對(duì)于復(fù)雜 SQL 性能較好,但是生成執(zhí)行計(jì)劃的時(shí)間也更久。
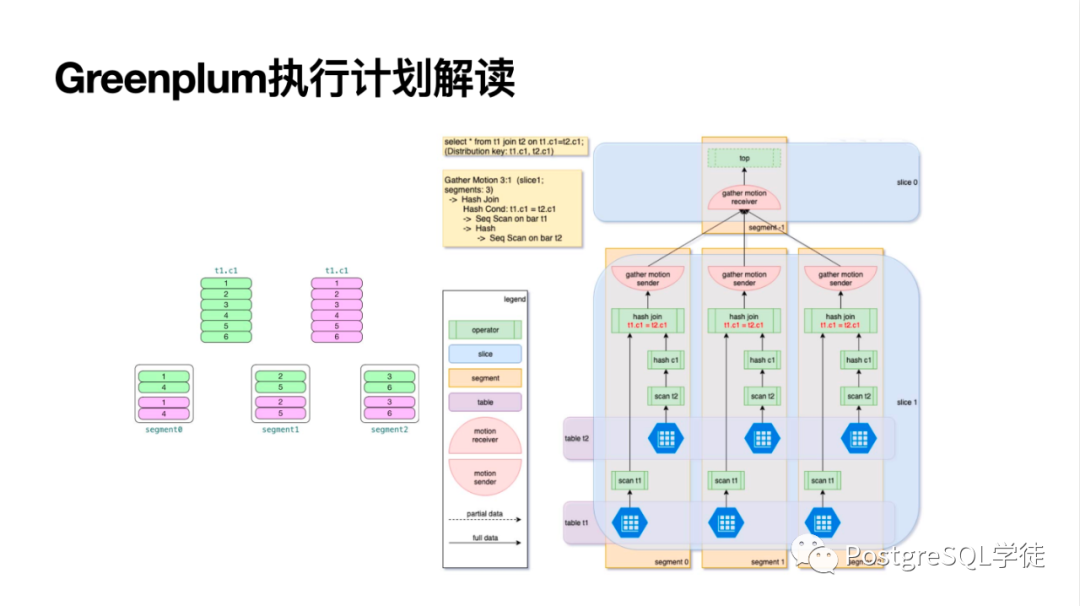
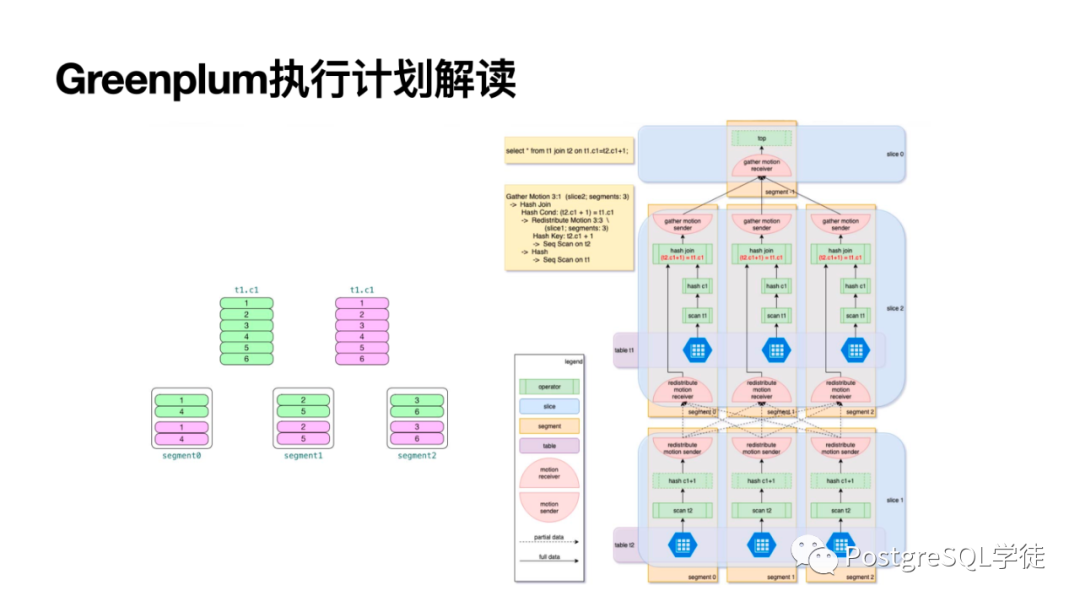
讓我們看一個(gè)實(shí)際的例子 (Greenplum 相較于 PostgreSQL 多了一些算子和術(shù)語(yǔ)) :
這里主要提一下 rows 的預(yù)估,各位可以參照我之前寫的執(zhí)行計(jì)劃篇章,根據(jù) pg_stats 統(tǒng)計(jì)信息計(jì)算而來(lái),這也再次說(shuō)明了統(tǒng)計(jì)信息的重要性,不然優(yōu)化器無(wú)從下手。
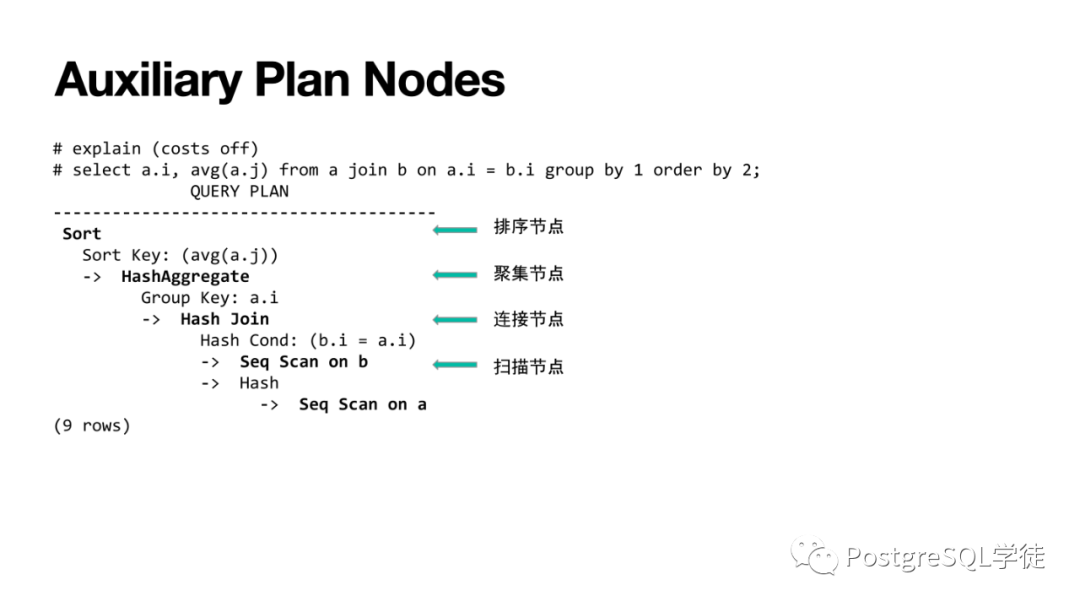
當(dāng)然還有各種各樣的輔助算子,用于執(zhí)行某些特定操作,比如
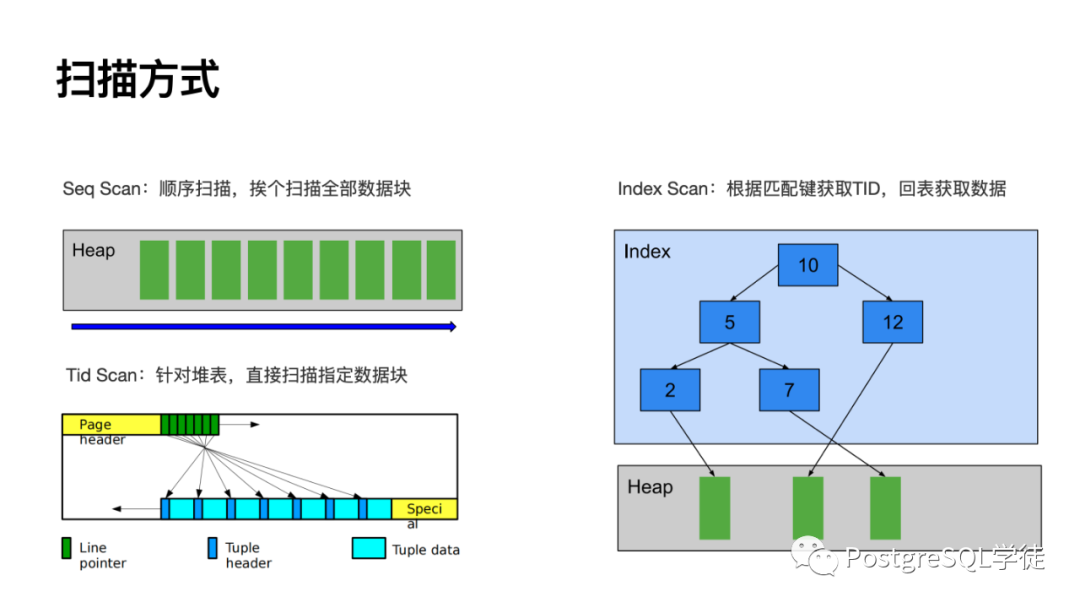
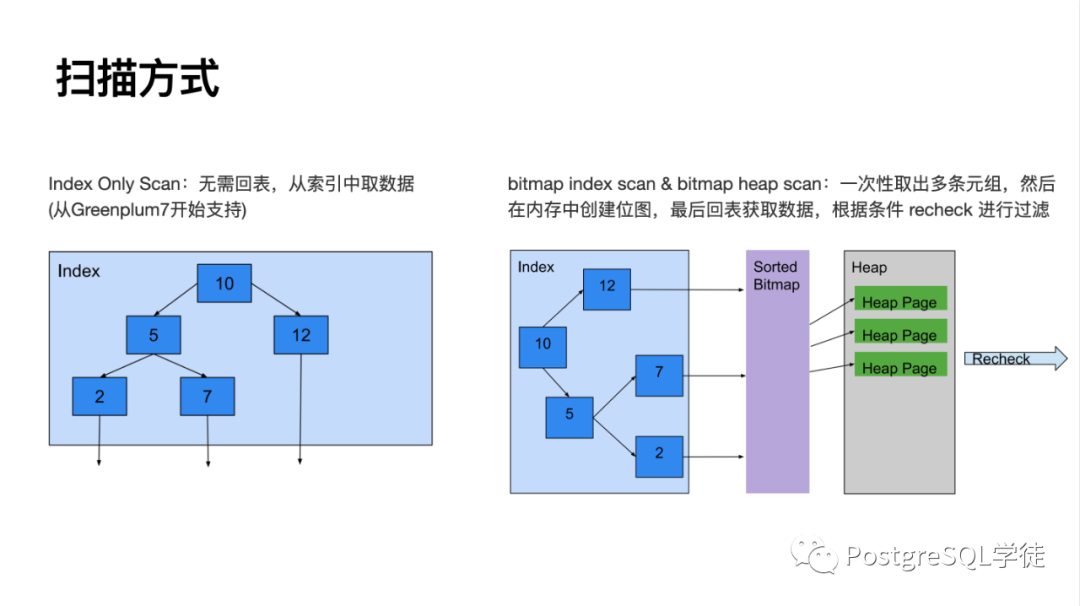
掃描方式就不多說(shuō)了,順序掃描 / 索引掃描 / bitmap scan,不過 Greenplum 是支持 bitmap 索引的。
對(duì)于向量化計(jì)算,各位可能也經(jīng)常在各大產(chǎn)品 PR 里面聽到,此處推薦閱讀一下 PgSQL · 引擎介紹 · 向量化執(zhí)行引擎簡(jiǎn)介 “
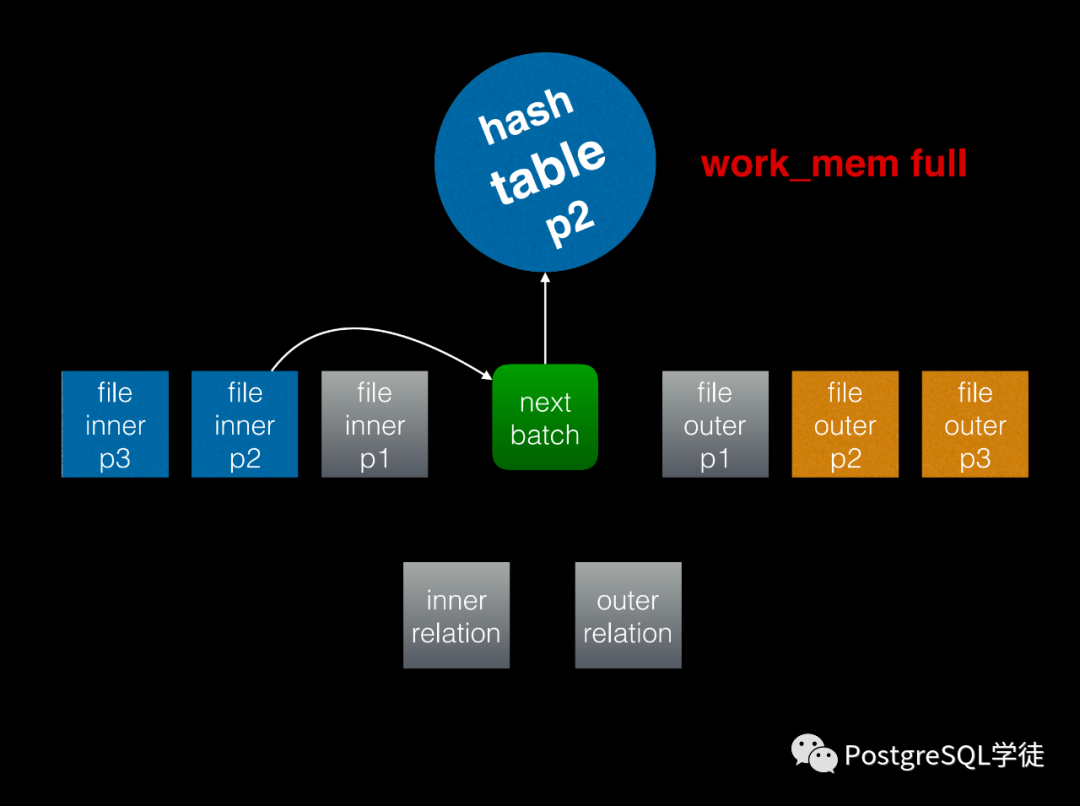
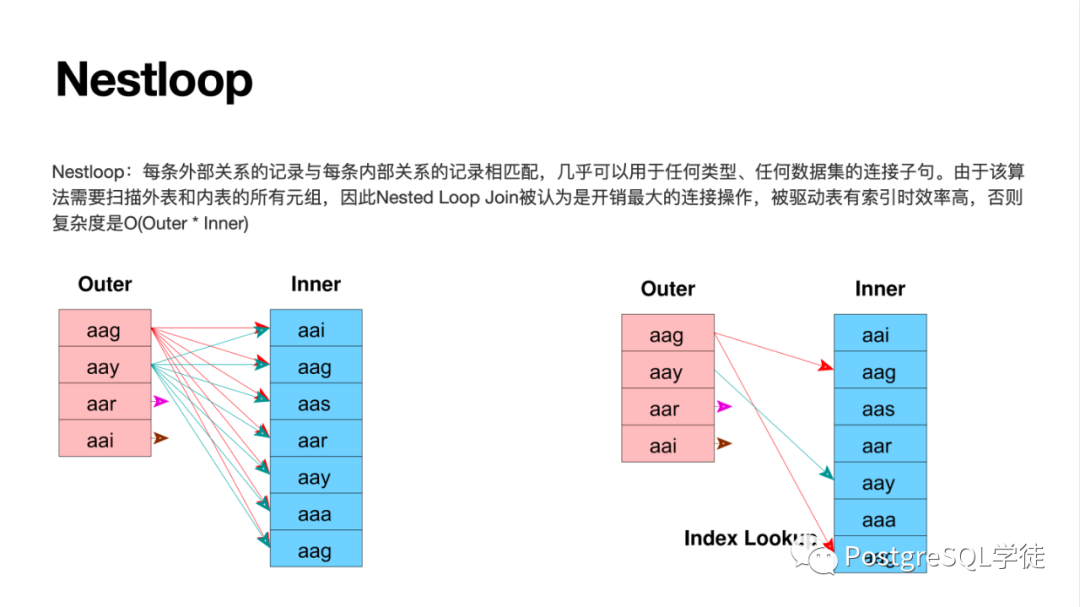
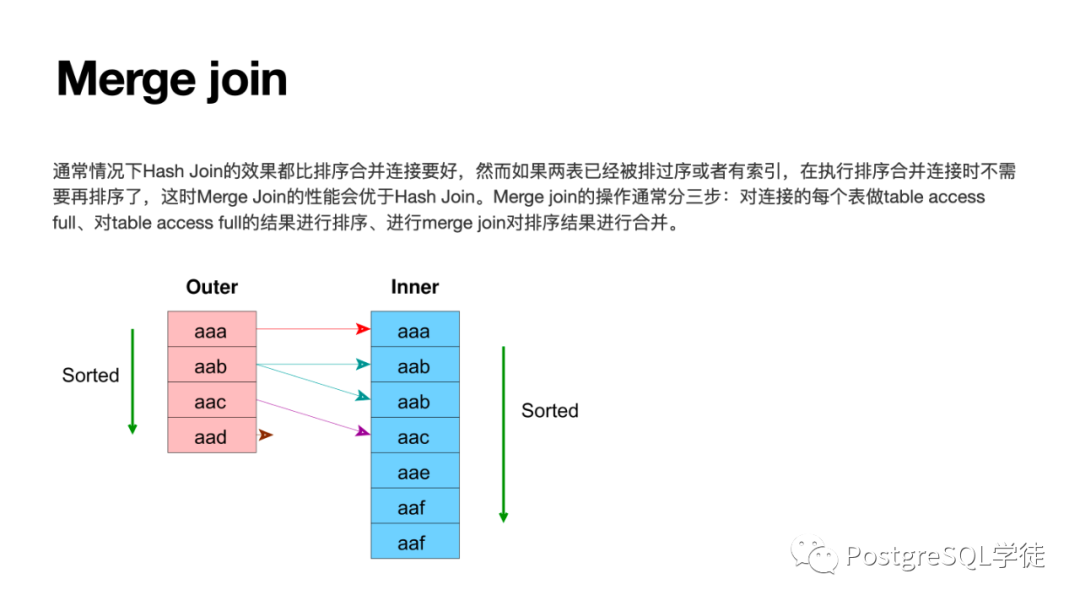
多表關(guān)聯(lián)的算法包括 NSL / HASH JOIN / MERGE JOIN,HASH JOIN 要關(guān)注批次 "batch" 的問題
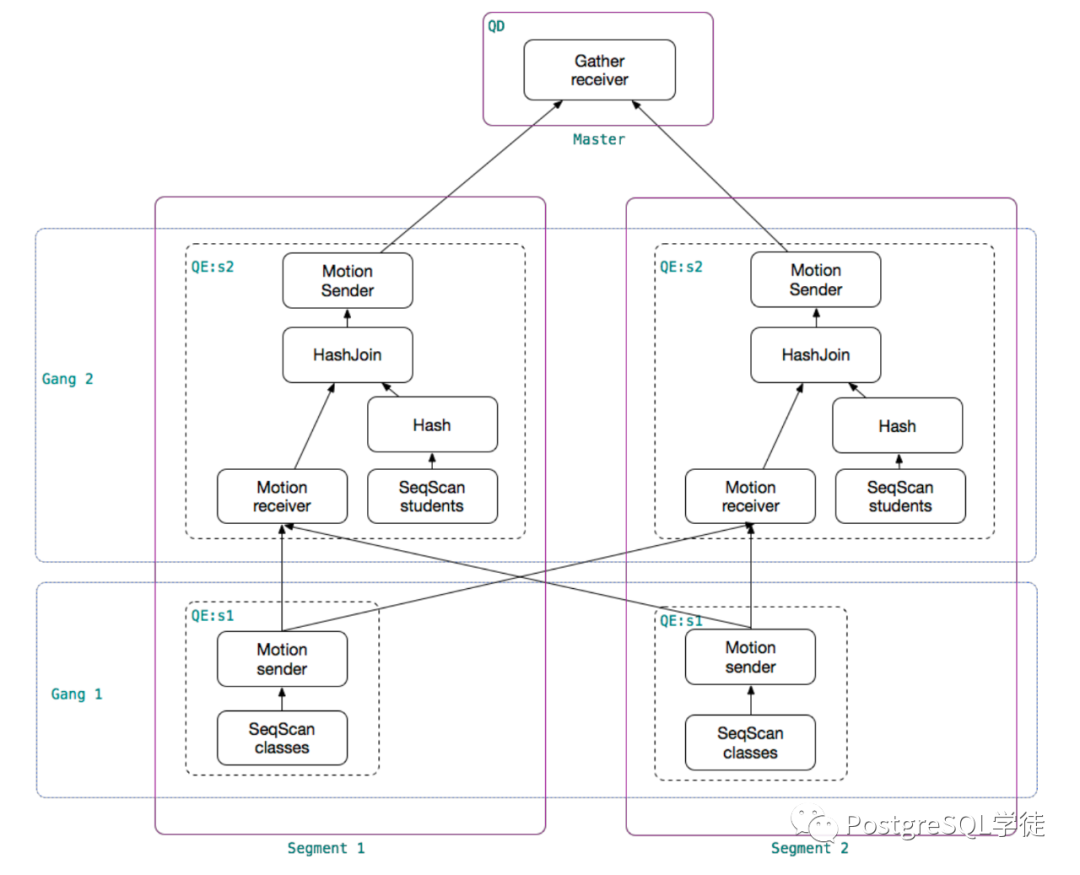
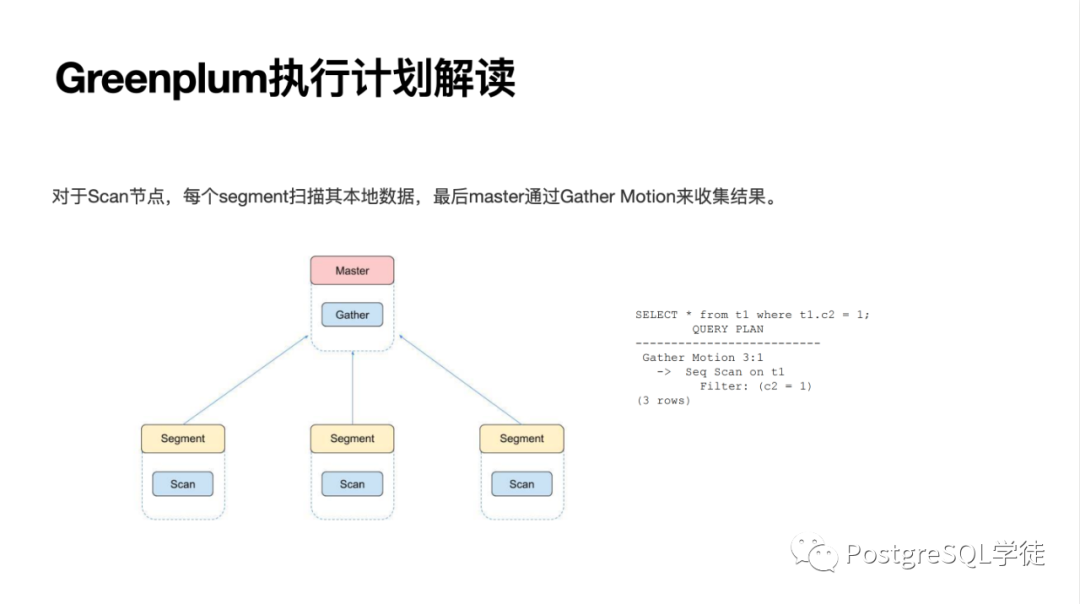
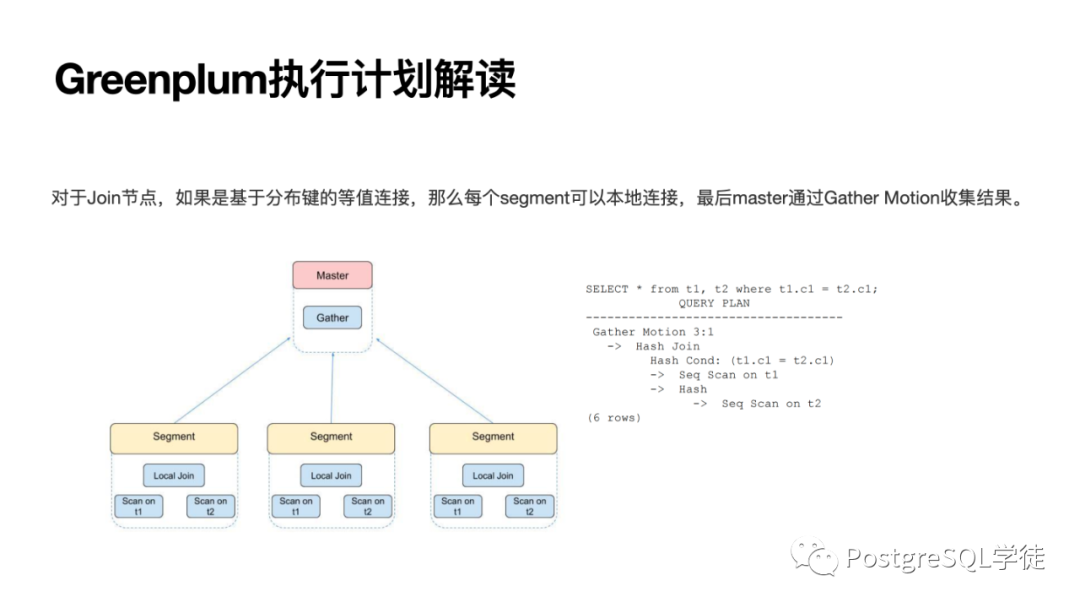
讓我們回到 Greenplum,Greenplum 不同于集中式 PostgreSQL,由多個(gè) segment + master 組成,master 僅僅是存放元信息,做結(jié)果的匯總 (Gather)
對(duì)于 JOIN,如果是基于分布鍵的等值連接 (因?yàn)橥瑯拥臄?shù)據(jù)都位于同一個(gè)數(shù)據(jù)節(jié)點(diǎn)),那么每個(gè) segment 可以本地連接,最后通過 Gather Motion 收集結(jié)果即可。
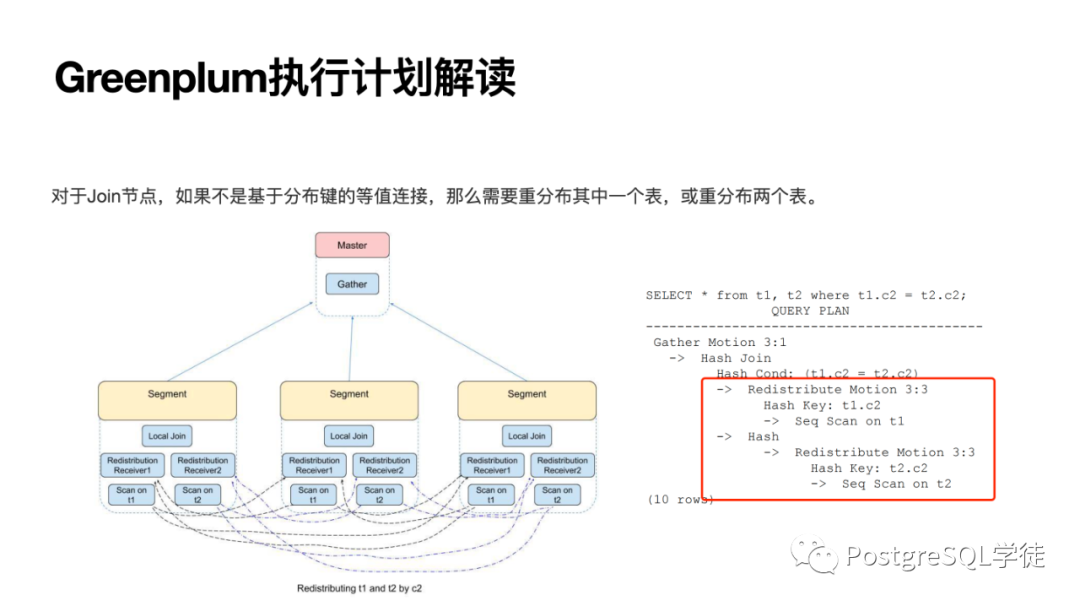
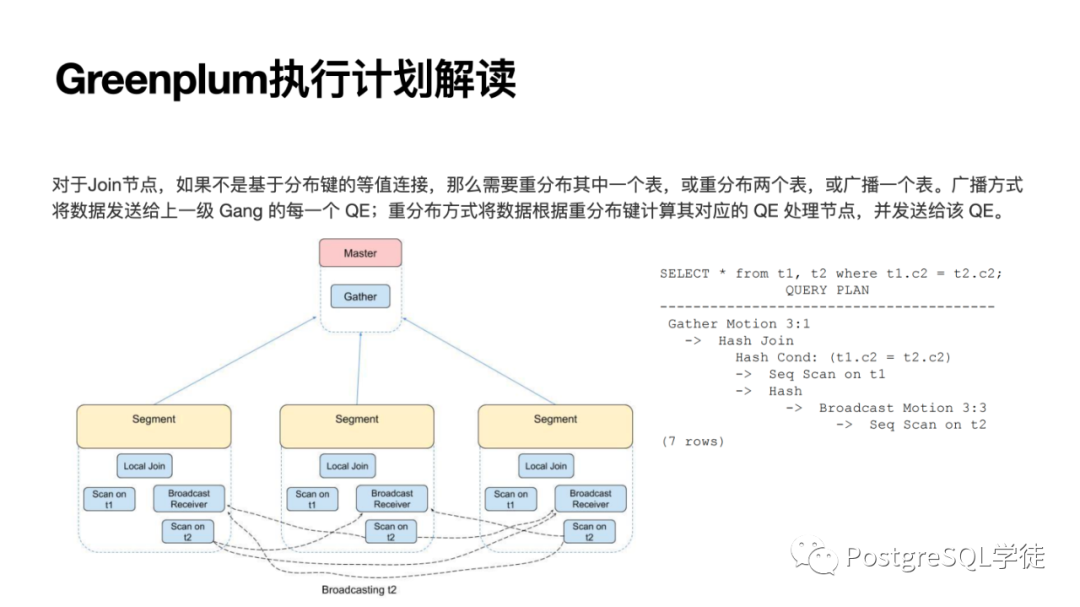
相反,如果不是基于分布鍵的等值連接,那么需要重分布其中一個(gè)表,或重分布兩個(gè)表,或者廣播,因?yàn)槲倚枰臄?shù)據(jù)位于其他節(jié)點(diǎn)上了,需要將數(shù)據(jù)傳輸?shù)街付ü?jié)點(diǎn)進(jìn)行關(guān)聯(lián)。
比如這個(gè)計(jì)劃,就很明顯,沒有涉及到重分布 (redistribute),而第二個(gè)由于不是分布鍵,就涉及到了重分布。
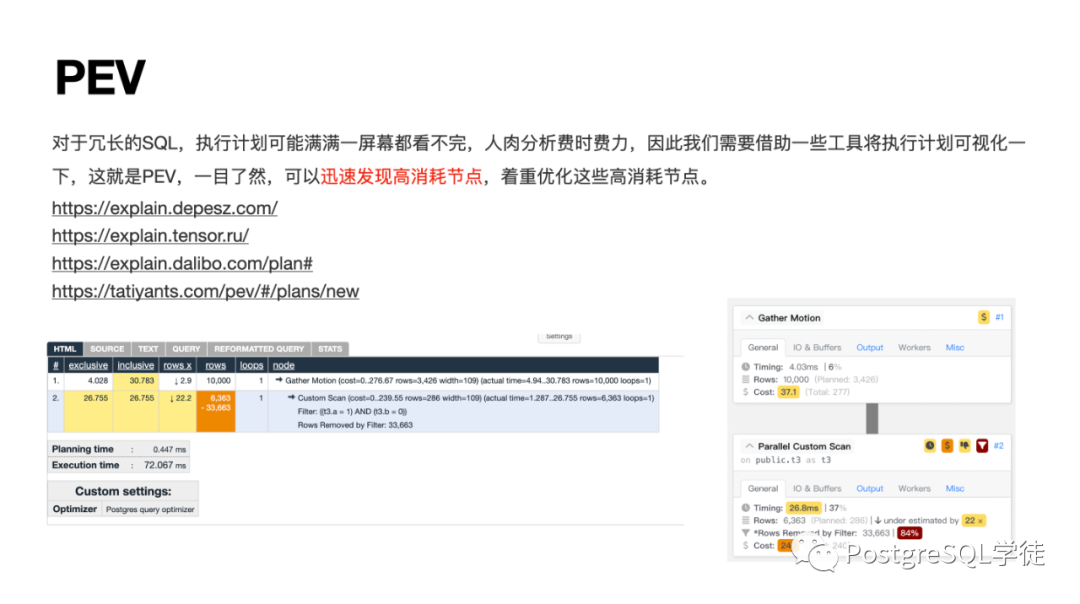
對(duì)于冗長(zhǎng)的 SQL,執(zhí)行計(jì)劃可能滿滿一屏幕都看不完,人肉分析費(fèi)時(shí)費(fèi)力,因此我們需要借助一些工具將執(zhí)行計(jì)劃可視化一下,這就是 PEV,一目了然,可以迅速發(fā)現(xiàn)高消耗節(jié)點(diǎn),著重優(yōu)化這些高消耗節(jié)點(diǎn),用得較多的是 "大力波"。
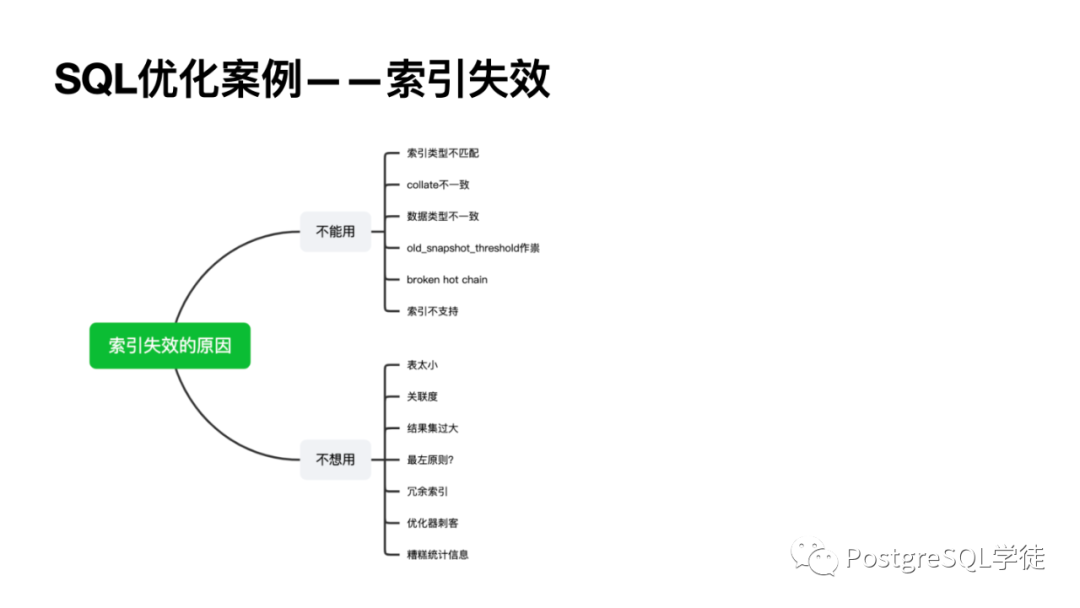
現(xiàn)在,讓我們看一下實(shí)際的優(yōu)化案例,老生常談的當(dāng)然是索引失效了,各位就直接看 PPT 吧。
關(guān)于分區(qū)裁剪,Greenplum7 里看著無(wú)法裁剪 stable 的函數(shù),有環(huán)境的讀者可以測(cè)一下,也歡迎讀者告訴下我結(jié)果。
內(nèi)存對(duì)齊我也提及過很多次,由于 CPU 取址是按照"模子" 去取的,存在著對(duì)齊。由于 Greenplum 存在行存表,AOCO 和 AORO ,此處針對(duì)傳統(tǒng)堆表,推薦字段排放順序如下:
一個(gè)小小的規(guī)范,可能就讓你從原來(lái)需要 40C 資源,降低到了 35C,何樂而不為呢。 另外前面也提到了,SQL 是一種聲明式的語(yǔ)言,what to do,而不是 how to do。對(duì)于一條 SQL,數(shù)據(jù)庫(kù)可以有多種方式去執(zhí)行,條條大路通羅馬,比如順序掃描、索引掃描,多表連接的話又有 nestloop、hashjoin、mergejoin 等,需要有一種機(jī)制告訴它如何去選擇一條最優(yōu)的方式去生成執(zhí)行計(jì)劃,這就是統(tǒng)計(jì)信息的作用,知道數(shù)據(jù)的一個(gè)分布情況,比如高頻值,非重復(fù)值數(shù)量,是否有空值等等。 如果統(tǒng)計(jì)信息過舊,那么優(yōu)化器做出的決策可能就不準(zhǔn)確,我們可以根據(jù) pg_stat_all_tables.last_analyze和last_autoanalyze 查詢何時(shí)做了 analyze ,確保統(tǒng)計(jì)信息沒有過舊。
另外就是擴(kuò)展統(tǒng)計(jì)信息了,Greenplum7 源自 12 的內(nèi)核,所以也支持
由于 Greenplum 是分布式數(shù)據(jù)庫(kù),分布鍵的設(shè)計(jì)至關(guān)重要,分布鍵的設(shè)計(jì)應(yīng)遵循:數(shù)據(jù)均勻分布原則、本地操作原則和負(fù)載均衡原則。無(wú)特殊情況,不使用隨機(jī)分布。
比如下面這個(gè)例子,就存在著數(shù)據(jù)傾斜,另外兩個(gè)節(jié)點(diǎn)只能干瞪著另外一個(gè)節(jié)點(diǎn)熱火朝天,所以木桶效應(yīng)的預(yù)防尤為重要,對(duì)于所有需要設(shè)計(jì) shard key 的數(shù)據(jù)庫(kù)都是一樣。
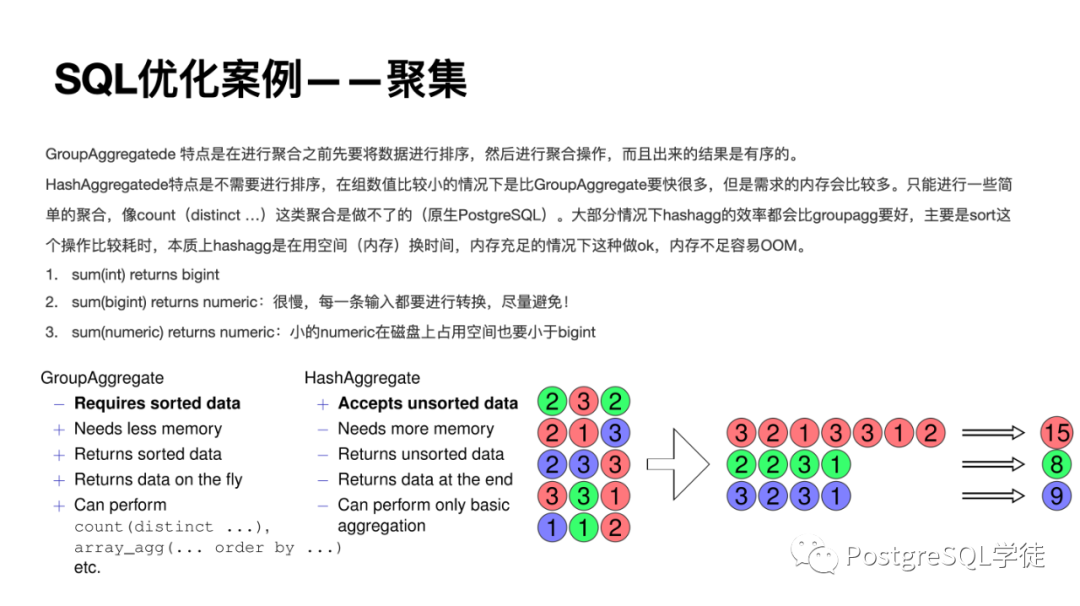
關(guān)于聚集,有兩種方式:
另外 HashAggregatede 只能進(jìn)行一些簡(jiǎn)單的聚合,像count (distinct …) 這類聚合是做不了的 (針對(duì)原生PostgreSQL 的情況),大部分情況下 HashAggregatede 的效率都會(huì)比 GroupAggregatede 要好,主要是排序這個(gè)操作比較耗時(shí),本質(zhì)上 GroupAggregatede 是在用空間 (內(nèi)存) 換時(shí)間,內(nèi)存充足的情況下這種做可以,但是內(nèi)存不足容易 OOM。
另外要尤其注意 sum(bigint) 的行為,會(huì)導(dǎo)致每一條數(shù)據(jù)都要轉(zhuǎn)換,盡量避免! 最后就是鮮為人知的 union all 了,關(guān)聯(lián)的數(shù)據(jù)類型最好保持一致!否則是無(wú)法做視圖展開的
可以看到這兩個(gè)查詢的效率天差地別,僅僅是因?yàn)閿?shù)據(jù)類型的原因
小結(jié)以上便是我個(gè)人關(guān)于 SQL 優(yōu)化的一點(diǎn)小心得,希望各位讀者閱讀之后能夠有所收獲。 該文章在 2023/11/15 22:20:58 編輯過 |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")