10倍提升你的SQL查詢速度
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
 作為一名數據分析師,SQL是必備技能之一。其優勢也比較明顯:易于理解,維護和擴展。然而,最大的挑戰在于,隨著數據量的增加,我們就會遇到延遲的瓶頸,或者說查詢太昂貴(耗時)而無法運行。 在這篇文章中我將會給出一些克服瓶頸的經驗,這些 tips 也許會讓延遲減小10倍甚至100倍。So,讓我們一起深入了解吧。 1. 理解 SQL 的查詢順序SQL 就像一個迷你版的編程語言,它按順序處理數據。 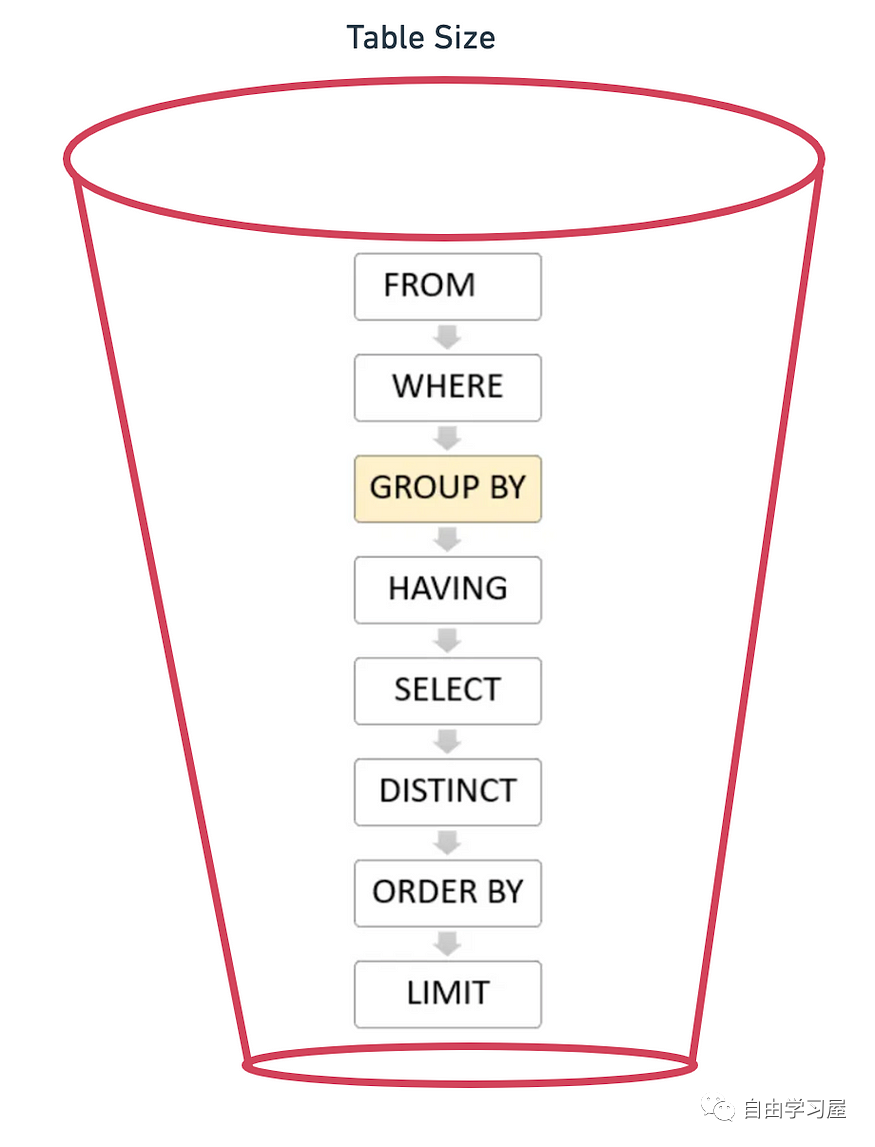 使用諸如“ 2. 用星型模式加快查詢速度在數據庫設計中,數據工程師喜歡對數據庫進行規范化,減少數據表之間的冗余,從而優化存儲、理清數據關系。然而,凡事皆有利弊,與之對應的缺點是查詢時需要多個連接和子查詢來對數據進行非規范化以提取所需的信息。 
為了加快查詢速度,建議首先對維度表進行非規范化或聯接,因為維度表通常較小并且聯接速度更快。之后,如果可能的話,與大型事實表連接。在上述情況下,請嘗試在查詢的最后一步處理大型銷售表。根據前人的實踐經驗,遵循這一理念通常可以將查詢速度提高 10 倍左右。 3. 通過了解關鍵索引將查詢速度提高 100 倍在下面的示例中,用戶可以按時間或按列遍歷/查詢數據。從視覺上看,按時間(逐行)或按列遍歷數據,時間復雜度可能不會有太大差異。  然而,實際上,數據并不是以連續的方式存儲的。它更像是一個鏈表數據結構。通過時間查詢與通過列查詢之間存在巨大差異。 如下圖所示,通過在查詢中使用時間索引,您可以輕松地將遍歷時間或查詢時間縮短10倍。隨著列數量的增加,效率增益甚至更大。國外某小哥親述在其項目工作中,在處理大型表(數 GB 數據)時,他們將查詢時間從 41 天縮短到大約 40 分鐘,速度提高了約 100 倍。 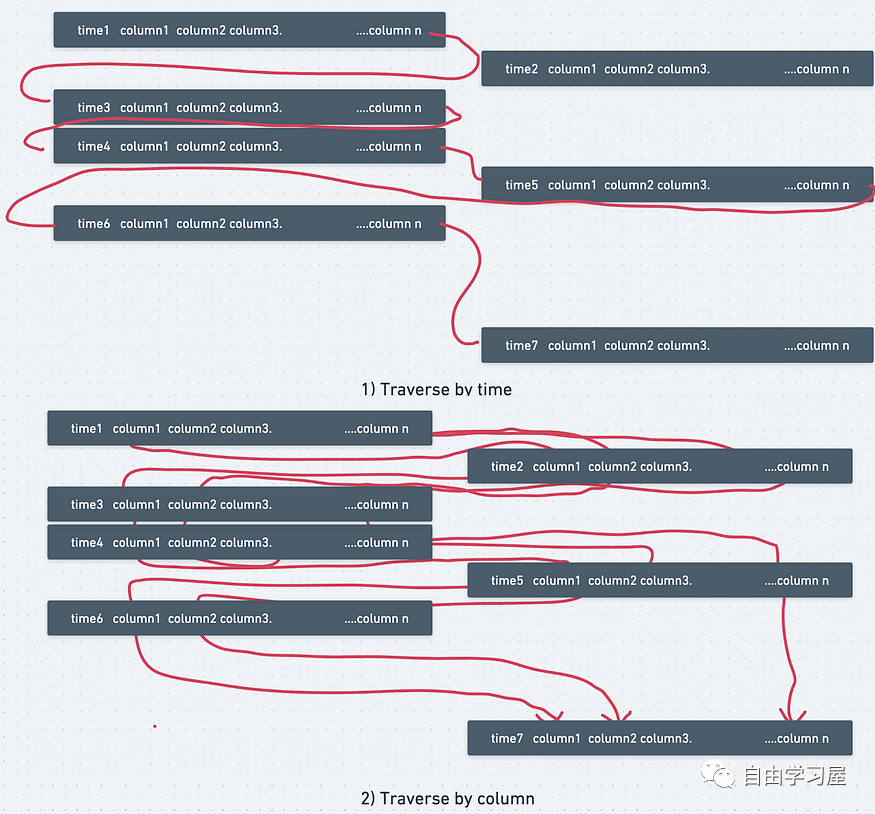 在這種情況下,基于時間塊運行的查詢可能比按列運行的查詢快 10 到 100 倍,因為數據庫是按時間索引的。 此外,您可以要求數據分析師或數據工程師根據您的業務需求重新索引您的數據庫。 -- two queries to pull large data datable 4. 利用 Python 的能力在現實項目中,完成上述步驟后,由于 SQL 的帶寬或數據庫服務器的計算能力瓶頸,你的 SQL 查詢仍然不夠快。 這個時候就可以使用 Python/Pandas 將中間表緩存到本地驅動器或云驅動器,之后用戶就可以使用 Python 執行繁重的表連接或聚合步驟,這樣通常會比在數據庫中執行類似的步驟快得多。 下面是一個代碼示例,通過 Jupyter Notebook 執行 PostgreSQL 查詢并將查詢結果導出為 dataframe: 5. 總結在這篇文章中,我們總結了四種加快你 SQL 查詢速度的方式:
希望這篇文章對您有用,如果您有更好的技巧或建議,請與我們一同分享。 Thank you for your reading, happy querying!
該文章在 2023/11/16 20:36:36 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886



