收藏篇:SQL優化的36個建議!干貨滿滿!
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
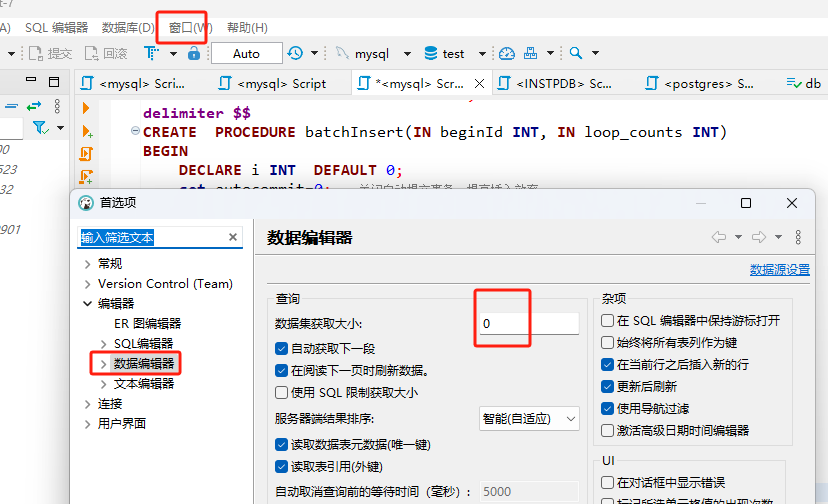
一、優化知識儲備1、mysql優化原則:盡量避免全表掃描、合理使用索引、避免返回大量數據給客戶端、避免使用游標、避免頻繁創建刪除臨時表。 聯表查詢時盡量用小表驅動大表,小的數據集驅動大的數據集,小表放左邊。 2、學會查看SQL執行計劃 explain select * from users; 速度排行: type: system > const > eq_ref > ref > range > index > ALL ---------------------------------------- ALL 全表掃描 index 掃描索引上全部數據,比ALL快一點 場景:count(*) range 范圍 user_id>200 ref 普通非唯一索引 user_name=100 eq_ref 唯一索引 const 唯一索引且條件是普通常量 user_id=100 system 系統表 3、SQL優化目標:優化到range及以上級別,index也很慢和ALL基本一樣。 4、注意客戶端自帶的limit會影響你的判斷。(干貨啊!!!這個一般百度上是沒有的,百度不到!!但是卻容易被忽視!!!) 客戶端一般都有默認帶上limit 200,比如dbeaver配置,可以關掉。 dbeaver 窗口-首選項-編輯器-數據編輯器 ,把數據集獲取大小改為0
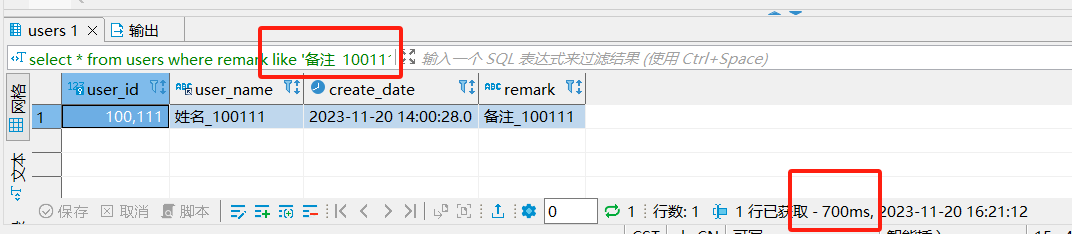
所以為什么大家經常測性能的時候,明明程序里面查詢很慢,在dbeaver里面卻很快,原因就是dbeaver可能偷偷給你加了limit 200。 這個在你測試性能的時候關掉,平時還是加上200的配置吧 5、用mysql自帶性能分析可以知道dbeaver默認加了limit 200 set profiling =1; select * from users where user_name =9000; show profiles; 二、盡量不做的事情1.盡量不在where條件用!= 或 <> 2.盡量不用 is null 和 is not null 3.盡量不用or 4.盡量不用like,如果一定要用就用右模糊 user_name like'xx%' 可以用explain驗證一下: 在字段已經建立索引的情況下: 'xx%' 走的是range執行計劃,前面說過range也是優化目標。 '%xx' 走ALL全表掃描 '%xx%' 走ALL全表掃描如果不是索引字段,那不管什么方式都是ALL全表掃描。 如果要用全模糊,那可以用全文索引解決like慢問題 某個段接like,那么這個字段是不走索引的,所以like就特別慢 ,要700ms
全文索引可以解決這個問題 -- 全文索引create fulltext index idx_users_remark on users(remark); 全文索引查詢方式:只要1ms select * from users where Match (remark) Against('備注_100111*' in boolean mode);
5.盡量不用 in not in 6.盡量不要在=左邊計算,或函數,如 where to_char(name)='xx' 7.不要用字符串作為主鍵 8.不要用select * select * 問題: 增加很多不必要的消耗,比如CPU、IO、內存、網絡帶寬; 增加了使用覆蓋索引的可能性; 增加了回表的可能性; 當表結構發生變化時,前端也需要更改; 查詢效率低; select * from users;--用時 2.1s
select user_id from users;--用時 453ms
9. 不要用group by having 來過濾,而是先在where 條件過濾后再group by. 10.盡量使得表連接不要超過5個 11.索引不是越多越好,會降低插入更新的速度,控制在5個以內 12.盡量避免使用游標 因為游標的效率較差,如果游標操作的數據超過1萬行,那么就應該考慮改寫。 13.索引不適合建在有大量重復數據的字段上,比如性別,排序字段應創建索引 14.盡量不要存儲圖片、文件等大數據。 15.單表數據最好不要超過500w,超過2000w速度明顯變慢。 16.in 內數據盡量不要太多,如果是連續的就用between代替。 17.不要在varchar字段上用數字查詢,否則會導致索引失效。 比如 user_name =1234 要改成 user_name='1234' 18.復合索引(a,b,c),不要單獨用b、c、或者bc進行查詢。 復合索引最左原則:a 、ab、abc、ac 都是能用上索引的。 (a,b,c) 為復合索引 ,那么它滿足最左原則。什么意思?where a=xx 走索引,其他情況呢 a 走索引 a,b 走索引 , 順序可以變 ba 也走,mysql會優化位置 a,c 走索引 a,b,c 走索引 b 不走索引 ,為什么這么說,它走的是index,和全表掃描ALL幾乎沒區別,慢的要死 c 不走索引 , 為什么這么說,它走的是index,和全表掃描ALL幾乎沒區別,慢的要死 bc 不走索引 就說,必須從最左邊開始都要有。 19.主鍵是自帶唯一索引的,因此不需要再在主鍵上建索引。 三、盡量要做的事情1.復合索引應該要第一個作為條件,否則不生效。 2.能用between 就不要用in 3.exists 代替in 4.數字型字段盡量用number別用varchar 5.查詢條件盡量使用上索引 6.varchar代替char varchar 可變,存多少占多少空間;char如果存的不夠會補空格。 7.left join 左邊放小表(數據量少的表) 8. 盡量使用limit 可以提高查詢速度,避免全表掃描。 9.批量插入提高性能。 10.查詢使用最頻繁的列放在聯合索引的最左側。 INSERT INTO users (user_id,user_name) VALUES(1,'aaa'),(2,'bbb'); 11.財務、銀行相關的金額字段必須使用decimal類型 非精準浮點:float,double 精準浮點:decimal Decimal類型為精準浮點數,在計算時不會丟失精度; 占用空間由定義的寬度決定,每4個字節可以存儲9位數字,并且小數點要占用一個字節; 可用于存儲比bigint更大的整型數據; 12.建議把BLOB或是TEXT列分離到單獨的擴展表中 Mysql內存臨時表不支持TEXT、BLOB這樣的大數據類型,如果查詢中包含這樣的數據,在排序等操作時,就不能使用內存臨時表,必須使用磁盤臨時表進行。而且對于這種數據,Mysql還是要進行二次查詢,會使sql性能變得很差,但是不是說一定不能使用這樣的數據類型。 如果一定要使用,建議把BLOB或是TEXT列分離到單獨的擴展表中,查詢時一定不要使用select * 而只需要取出必要的列,不需要TEXT列的數據時不要對該列進行查詢。 該文章在 2024/1/22 8:54:26 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886