大模型長(zhǎng)上下文運(yùn)行的關(guān)鍵問(wèn)題
當(dāng)前位置:點(diǎn)晴教程→閑情逸致
→『 微信好文 』
上下文長(zhǎng)度的增加是 LLM 的一個(gè)顯著發(fā)展趨勢(shì)。過(guò)去一年,幾種長(zhǎng)上下文語(yǔ)言模型陸續(xù)問(wèn)世,包括 GPT-4(32k上下文)、MosaicML 的 MPT(65k上下文)、Anthropic 的 Claude(100k上下文)等。然而,擴(kuò)大 Transformer 的上下文長(zhǎng)度是一個(gè)挑戰(zhàn),因?yàn)槠浜诵牡淖⒁饬釉跁r(shí)間復(fù)雜度和空間復(fù)雜度與輸入序列長(zhǎng)度的平方成正比。
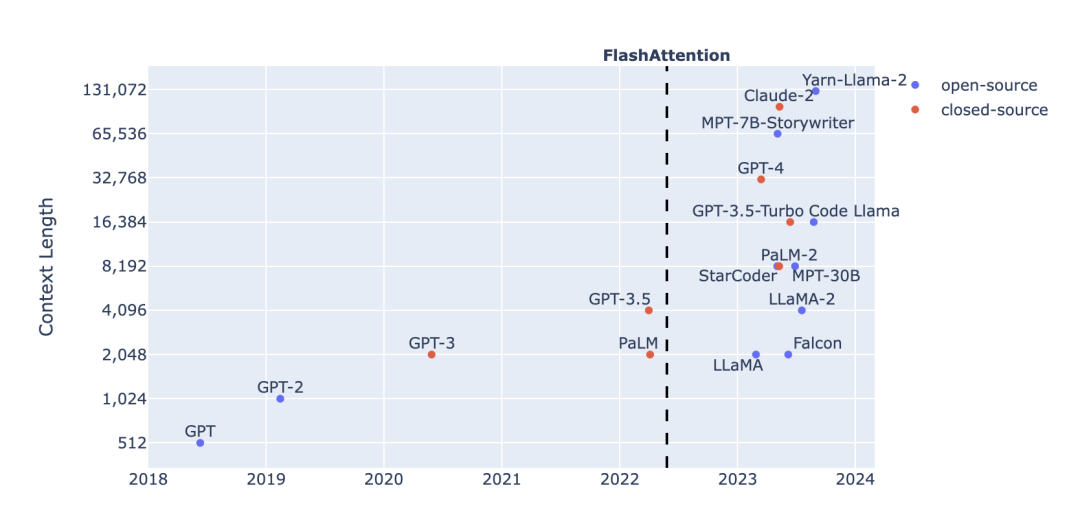
本文作者 Harm de Vries 是 ServiceNow 的研究員,也是其 LLM 實(shí)驗(yàn)室的負(fù)責(zé)人。他認(rèn)為,長(zhǎng)上下文運(yùn)行的問(wèn)題在于缺少長(zhǎng)預(yù)訓(xùn)練數(shù)據(jù),而非二次注意力。 本文將深入探討隨上下文長(zhǎng)度的增加,注意力層的計(jì)算開(kāi)銷情況,并指出常見(jiàn)預(yù)訓(xùn)練數(shù)據(jù)集中序列長(zhǎng)度的分布情況。由此,作者針對(duì)長(zhǎng)上下文運(yùn)行分析了幾個(gè)重要問(wèn)題:是否在固有短序列數(shù)據(jù)上浪費(fèi)了注意力計(jì)算開(kāi)銷?如何創(chuàng)建有意義的長(zhǎng)文本預(yù)訓(xùn)練數(shù)據(jù)?是否可以在訓(xùn)練過(guò)程中使用可變的序列長(zhǎng)度?以及如何評(píng)估長(zhǎng)上下文能力? (以下內(nèi)容在遵循 CC BY-NC-SA 4.0 協(xié)議的基礎(chǔ)上由 OneFlow 編譯發(fā)布,譯文轉(zhuǎn)載請(qǐng)聯(lián)系授權(quán)。原文:https://www.harmdevries.com/post/context-length/) 作者 | Harm de Vries OneFlow編譯 翻譯|楊婷、宛子琳 長(zhǎng)上下文運(yùn)行的問(wèn)題在于缺少長(zhǎng)預(yù)訓(xùn)練數(shù)據(jù),而不是二次注意力。 上下文長(zhǎng)度增加是語(yǔ)言大模型的一個(gè)顯著趨勢(shì)。上下文長(zhǎng)度是指在 Transformer 預(yù)測(cè)下一個(gè)詞元之前,我們可以喂入到模型中的詞元數(shù)量。過(guò)去一年,長(zhǎng)上下文 LLM(Long-context LLM)的數(shù)量顯著增加,如下圖所示。
FlashAttention 的發(fā)明是一個(gè)重要的轉(zhuǎn)折點(diǎn),它以一種巧妙的方式適應(yīng)了現(xiàn)代 GPU 對(duì)注意力計(jì)算的需求,提高了計(jì)算和內(nèi)存效率。本文不會(huì)詳細(xì)介紹 FlashAttention 的技術(shù)細(xì)節(jié),但它消除了 GPU 的內(nèi)存瓶頸,使 LLM 開(kāi)發(fā)者能夠?qū)⑸舷挛拈L(zhǎng)度從傳統(tǒng)的 2K 詞元增加至 8-65K。 有趣的是,如果你仔細(xì)觀察長(zhǎng)上下文 LLM,就會(huì)發(fā)現(xiàn)其中許多都是由較小上下文窗口的基礎(chǔ) LLM 微調(diào)而來(lái)的。例如:
為什么會(huì)有這兩個(gè)訓(xùn)練階段呢?共有兩種可能:(1)由于注意力層的二次復(fù)雜性,使用長(zhǎng)上下文進(jìn)行訓(xùn)練在計(jì)算上太過(guò)昂貴;(2)預(yù)訓(xùn)練階段缺乏長(zhǎng)序列數(shù)據(jù)。 本文將深入探討以上兩點(diǎn):
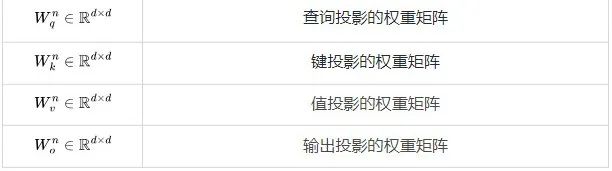
綜合上述觀察結(jié)果,可以得出結(jié)論:雖然使用 16-32K 上下文窗口進(jìn)行預(yù)訓(xùn)練是可行的,但個(gè)別文檔的詞元分布并不適合這種方法。主要問(wèn)題在于,傳統(tǒng)的預(yù)訓(xùn)練方法將來(lái)自隨機(jī)文件的詞元打包到了上下文窗口中,這導(dǎo)致 16-32K 的詞元窗口中包含了許多不相關(guān)的文檔。假設(shè)在預(yù)訓(xùn)練期間,LLM 能受益于更具意義的長(zhǎng)上下文,本文認(rèn)為可利用元數(shù)據(jù)創(chuàng)建更長(zhǎng)的預(yù)訓(xùn)練數(shù)據(jù),例如通過(guò)超鏈接連接網(wǎng)頁(yè)文檔,以及通過(guò)代碼庫(kù)結(jié)構(gòu)連接代碼文件。 1上下文長(zhǎng)度對(duì) Transformer 浮點(diǎn)運(yùn)算(FLOP)的影響讓我們從注意力層的計(jì)算開(kāi)銷開(kāi)始。我們將估算訓(xùn)練 Transformer 模型所需的計(jì)算量。具體來(lái)說(shuō),我們將計(jì)算模型在前向傳播和反向傳播過(guò)程中的矩陣乘法所需的浮點(diǎn)運(yùn)算(FLOPs)。為更好地進(jìn)行研究,我們將 FLOPs 分為三組:前饋層(FFN)中的稠密層,查詢、鍵、值、輸出的投影(QKVO),以及計(jì)算查詢-鍵(query-key)得分和值嵌入(value embeddings)的加權(quán)求和(Att)。 對(duì)于具有
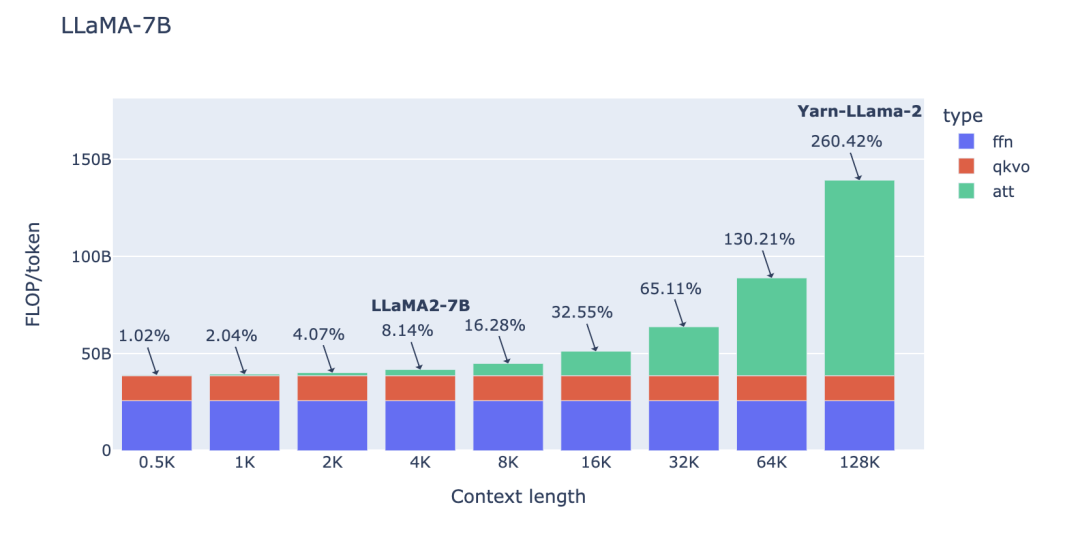
可參閱附錄以獲取詳細(xì)推導(dǎo)過(guò)程https://www.harmdevries.com/post/contextlength/#appendix)。值得強(qiáng)調(diào)的是,我們研究 FLOPs/token 以便在不同上下文長(zhǎng)度之間進(jìn)行有意義的比較。同時(shí)請(qǐng)注意, 現(xiàn)在讓我們研究一下上述三項(xiàng)在增加上下文長(zhǎng)度時(shí)對(duì)總 FLOPs/token 的貢獻(xiàn)。下面,我們展示了 LLaMA-7B 模型的細(xì)分情況,其中
如圖所示,對(duì)于 4K 的上下文窗口,注意力 FLOPs 的貢獻(xiàn)相對(duì)較小(8%)。這是 LLaMA-2 和其他幾個(gè)基礎(chǔ) LLM 模型的預(yù)訓(xùn)練階段,其中注意力 FLOPs 對(duì)計(jì)算的影響可以忽略不計(jì)。然而,當(dāng)使用 128K 的超大上下文窗口(如 Yarn-Llama-2)時(shí),注意力 FLOPs 就成了主導(dǎo)因素,造成了 260% 的計(jì)算開(kāi)銷。 這意味著,如果使用 2K 上下文窗口進(jìn)行完整的預(yù)訓(xùn)練需要 1 周時(shí)間,那么使用 128K 的上下文長(zhǎng)度則預(yù)計(jì)需要 3.5 周的時(shí)間。當(dāng)然,這是在訓(xùn)練過(guò)程中使用的詞元數(shù)相同(例如通過(guò)減小批量大小)的情況下。考慮到計(jì)算時(shí)間的大幅增加,許多研究和開(kāi)發(fā)人員只愿意在微調(diào)階段承擔(dān)這樣的開(kāi)銷。在這兩個(gè)極端之間存在這一個(gè)有吸引力的折中方案,例如,使用 8-16K 的上下文窗口只會(huì)增加 16-33% 的計(jì)算開(kāi)銷,這是可以接受的。這就是我們?yōu)?StarCoder 選擇的折中方案,它使用 8K 的上下文長(zhǎng)度,用超過(guò) 1 萬(wàn)億個(gè)詞元進(jìn)行了預(yù)訓(xùn)練。 許多人往往低估了模型大小對(duì)注意力計(jì)算開(kāi)銷的影響程度。無(wú)論是 FFN FLOPs、QKVO FLOPs(以及模型參數(shù))都與隱藏狀態(tài)維度
對(duì)于 GPT3-170B( 總的來(lái)說(shuō),我認(rèn)為在當(dāng)前的模型規(guī)模下,使用 16-32K 范圍內(nèi)的基礎(chǔ)模型進(jìn)行訓(xùn)練是非常合理的。正如我將在接下來(lái)的部分中解釋的,目前的主要瓶頸是數(shù)據(jù)集不適合使用如此長(zhǎng)的上下文進(jìn)行預(yù)訓(xùn)練。 2預(yù)訓(xùn)練數(shù)據(jù)的序列長(zhǎng)度接下來(lái),我們將研究常見(jiàn)的預(yù)訓(xùn)練數(shù)據(jù)集中的序列長(zhǎng)度分布,首先來(lái)觀察下表中 LLaMA 模型的訓(xùn)練數(shù)據(jù)。
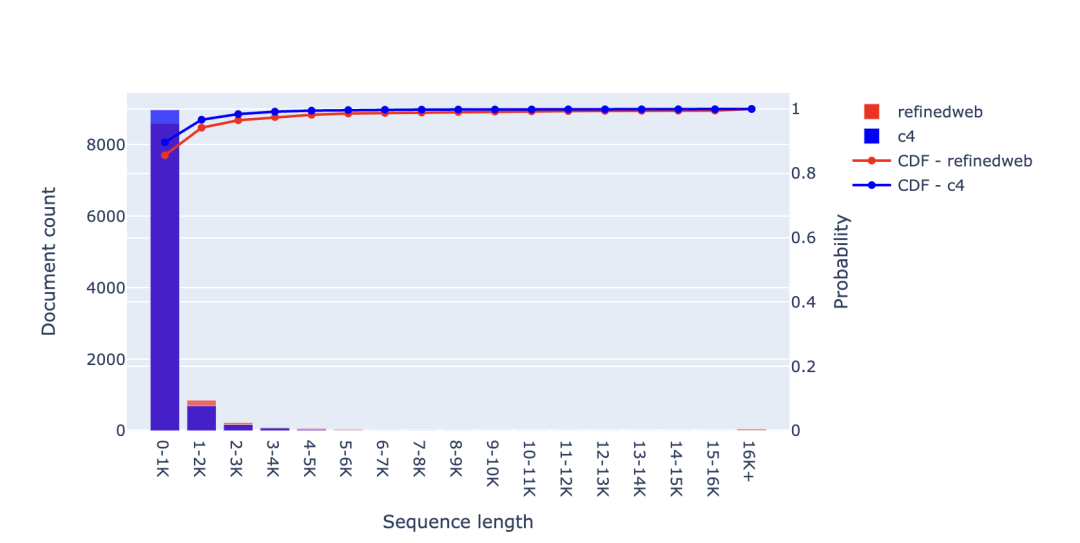
可以看到,CommonCrawl 是 LLaMA 訓(xùn)練數(shù)據(jù)集的主要數(shù)據(jù)來(lái)源,CommonCrawl 是一個(gè)公開(kāi)可用的互聯(lián)網(wǎng)抓取數(shù)據(jù)集。實(shí)際上,C4 的數(shù)據(jù)也是從 CommonCrawl 中獲取的,因此這個(gè)數(shù)據(jù)源占據(jù)了 LLaMA 訓(xùn)練數(shù)據(jù)的 80% 以上。其他數(shù)據(jù)來(lái)源(如Github、ArXiv、Wikipedia和書籍)只貢獻(xiàn)了一小部分訓(xùn)練數(shù)據(jù)。值得注意的是,MPT-30B 和 OpenLLaMA-7B 基本遵循了相同的數(shù)據(jù)分布,而 Falcon-40B 甚至僅使用了 CommonCrawl 數(shù)據(jù)進(jìn)行訓(xùn)練(參見(jiàn) RefinedWeb 數(shù)據(jù)集)。 相反,用于代碼的 LLM 通常是在 Github 的源代碼上進(jìn)行訓(xùn)練的。StarCoder、Replit-3B、CodeGen2.5 和 StableCode 都使用了 The Stack,這是一個(gè)包含了 Github 上許可放寬的代碼庫(kù)構(gòu)成的預(yù)訓(xùn)練數(shù)據(jù)集。 我們將分析這些預(yù)訓(xùn)練數(shù)據(jù)集的序列長(zhǎng)度分布,其中主要分析 CommonCrawl 和 Github,此外,我們還會(huì)分析一些較小的數(shù)據(jù)集(如 Wikipedia 和 Gutenberg 圖書),以供參考。對(duì)于每個(gè)數(shù)據(jù)源,我們將隨機(jī)選擇 10000 個(gè)樣本,對(duì)樣本進(jìn)行詞元化,并保存序列長(zhǎng)度。隨后,我們會(huì)創(chuàng)建柱狀圖以可視化序列長(zhǎng)度的分布情況,并查看每個(gè)區(qū)間(即文檔計(jì)數(shù))有多少文檔或文件。此外,我們還將評(píng)估每個(gè)區(qū)間內(nèi)的詞元數(shù)量,因?yàn)槲覀冏⒁獾揭恍┹^長(zhǎng)的文件可能會(huì)對(duì)統(tǒng)計(jì)數(shù)據(jù)產(chǎn)生較大的影響。需要注意的是,對(duì)于純文本數(shù)據(jù)源(CommonCrawl、Wikipedia、Gutenberg),我們使用的是 Falcon 分詞器,而處理源代碼(The Stack)時(shí),我們使用的是 StarCoder 分詞器。 2.1 CommonCrawl 首先,我們分析的是 CommonCrawl 數(shù)據(jù)集,并查看了 RefinedWeb 和 C4 數(shù)據(jù)集。從圖中可以看出,C4 和 RefinedWeb 中有相當(dāng)大一部分的文件都相對(duì)較短,其中超 95% 的文件包含的詞元不足 2K。因此,將上下文窗口擴(kuò)展到 2K 以上,只能為其中 5% 的文件捕獲更長(zhǎng)的上下文!
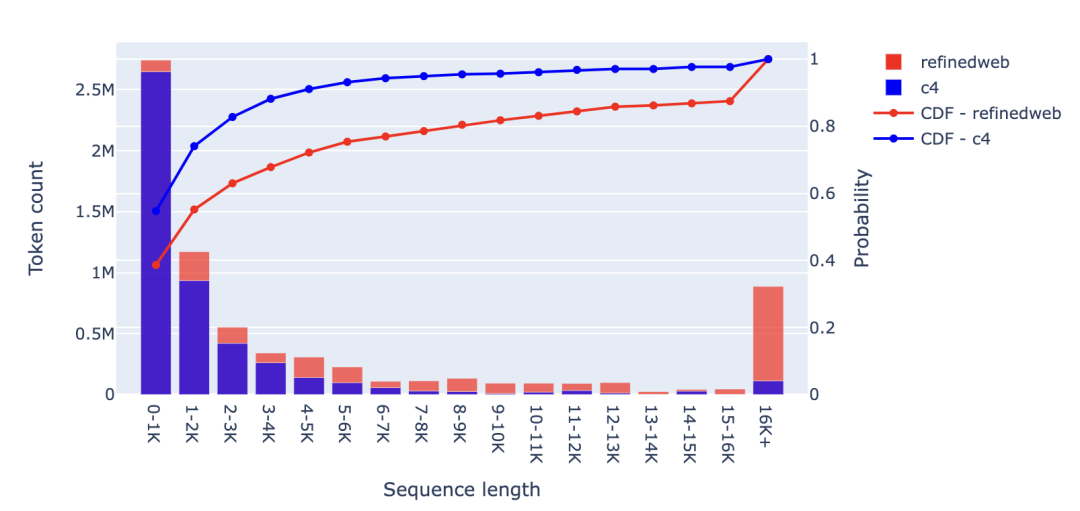
然而,你可能會(huì)認(rèn)為,我們關(guān)心的是每個(gè)區(qū)間內(nèi)的詞元數(shù)量而不是文件數(shù)量。確實(shí),當(dāng)我們觀察下圖中的詞元數(shù)量時(shí),情況略有不同。在 RefinedWeb 中,將近 45% 的詞元來(lái)自超 2K 個(gè)詞元的文件。因此,將上下文長(zhǎng)度增加到 2K 以上,對(duì)于 45% 的詞元來(lái)說(shuō)可能仍然是有益的。至于剩余的 55%,我們會(huì)將來(lái)自隨機(jī)文件的詞元連接到上下文窗口中。我認(rèn)為,這對(duì)模型的幫助不大,甚至可能影響模型性能。 如果我們將上下文窗口擴(kuò)展到 8K,那么幾乎有 80% 的詞元可以完全適應(yīng)上下文窗口,換言之,只有 20% 的詞元可能會(huì)從超 8K 的更長(zhǎng)上下文中受益。
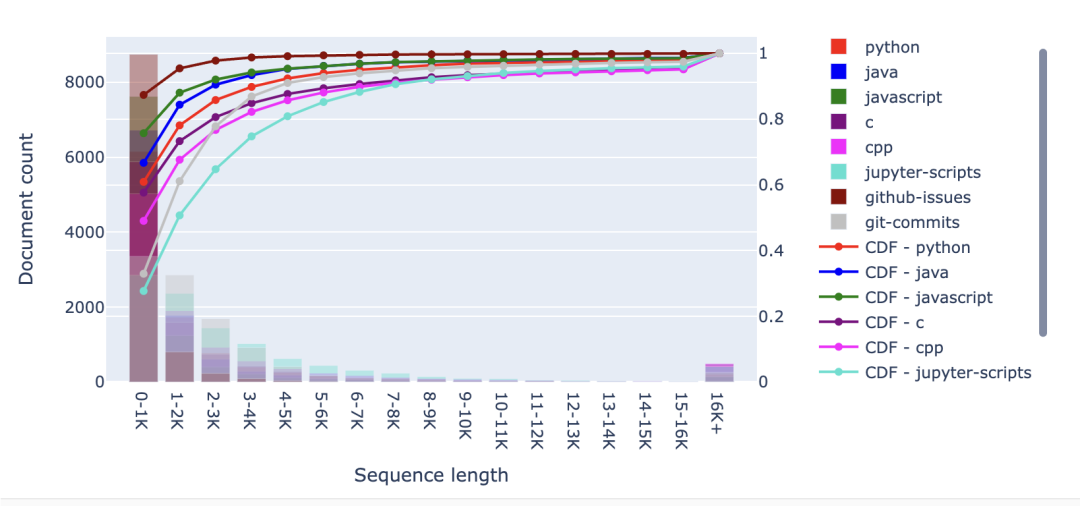
該圖表中還可以看出另一個(gè)明顯差異——即 RefinedWeb 數(shù)據(jù)集比 C4 數(shù)據(jù)集具有更多的長(zhǎng)文件。可以看到,RefinedWeb 中超過(guò) 16K 個(gè)詞元的文件占比超 12.5%,而 C4 則不到 2.5%。有趣的是,盡管這兩個(gè)數(shù)據(jù)集都來(lái)自同一來(lái)源,但其序列長(zhǎng)度分布的差異卻如此之大。 2.2 Github 接下來(lái),我們來(lái)看看 starcoderdata 中的不同編程語(yǔ)言、Github issues 和 Jupyter Notebook, starcoderdata 是用于訓(xùn)練 StarCoder 的 The Stack 子集。對(duì)于所有編程語(yǔ)言,我們可以觀察到大多數(shù)文件都很短:80% 以上的文件詞元量不超過(guò) 3K,Github issues 往往也比較短,只有 Jupyter Notebook 的上下文稍長(zhǎng),盡管超過(guò) 80% 的文件仍然少于 5K 詞元。
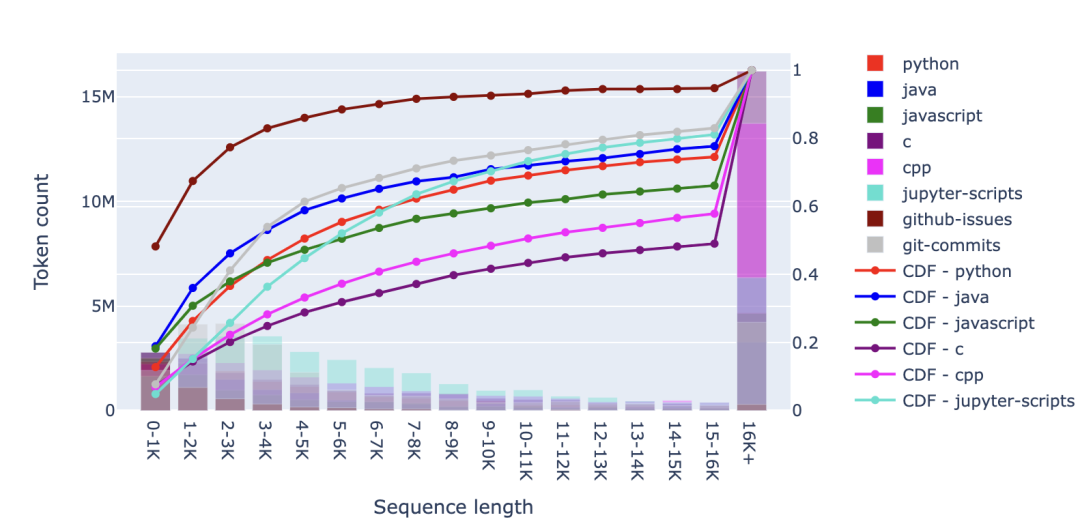
從文檔柱狀圖中,我們還可以看到 Github 中的長(zhǎng)文件比 CommonCrawl 多。當(dāng)我們觀察下面的詞元柱狀圖時(shí),這種長(zhǎng)尾效應(yīng)更加明顯。具體而言,在 C 編程語(yǔ)言的情況下,超 50% 的詞元來(lái)自于超 16K 個(gè)詞元的文件——盡管這些文件的比例不到 5%!在對(duì)這些長(zhǎng)文件進(jìn)行人工檢查時(shí),我發(fā)現(xiàn)有些文件的詞元超過(guò)了 300K。許多這樣的長(zhǎng)文件似乎是大型的宏和函數(shù)集合。當(dāng)然,你可能會(huì)質(zhì)疑這些文件中有多少是有意義的長(zhǎng)上下文結(jié)構(gòu)。
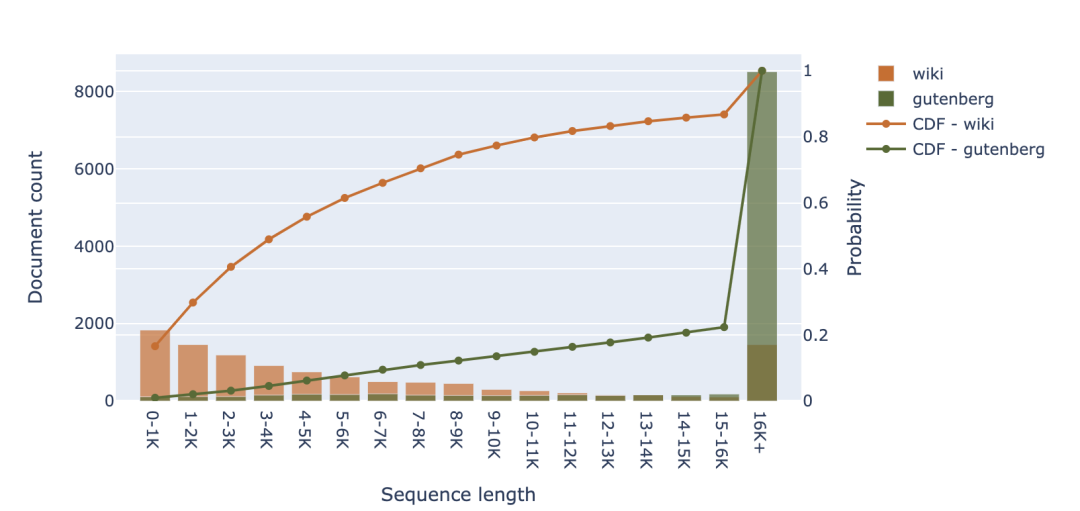
從更廣泛的視角來(lái)看,考慮到其他編程語(yǔ)言,可以明顯看到較長(zhǎng)的代碼文件比 Web 文檔更多。如果排除 C 語(yǔ)言和 Javascript,我們會(huì)發(fā)現(xiàn)大約 50-70% 的詞元來(lái)自少于 8,000 個(gè)詞元的文件,而對(duì)于 RefinedWeb 數(shù)據(jù)集,這一比例接近 80%。 2.3 其他資源 正如預(yù)期的那樣,我們可以在其他預(yù)訓(xùn)練數(shù)據(jù)來(lái)源(如 Wikipedia 和圖書)中可以找到更多的長(zhǎng)文檔。在下面的柱狀圖中,我們觀察到,超 50% 的 Wikipedia 文章的詞元數(shù)超過(guò)了 4000。就圖書而言(比如 LLaMA 數(shù)據(jù)集中包含的 Gutenberg 圖書集),我們甚至發(fā)現(xiàn)超 75% 的圖書含有超 16000個(gè)詞元。
盡管以上圖表證實(shí)這些數(shù)據(jù)源比 CommonCrawl 和 Github 具有更多的長(zhǎng)上下文結(jié)構(gòu),但它們?cè)谟?xùn)練數(shù)據(jù)中所占的比例通常較小。原因如下:首先這些數(shù)據(jù)源能夠提供的數(shù)據(jù)量有限,不適合大規(guī)模預(yù)訓(xùn)練,例如 Wikipedia 只包含約 80GB 數(shù)據(jù),而 CommonCrawl 則可以提供幾 TB 的數(shù)據(jù);其次,這些數(shù)據(jù)(例如圖書)的網(wǎng)絡(luò)覆蓋率不足,所以模型訓(xùn)練數(shù)據(jù)中的圖書比例也很少(LLaMA 為4.5%,MBT-30B 為3%)。 3 討論 3.1 是否在固有短序列數(shù)據(jù)上浪費(fèi)了注意力計(jì)算開(kāi)銷? 經(jīng)前文分析,可以看出 CommonCrawl 和 Github 是訓(xùn)練 SOTA 開(kāi)源語(yǔ)言模型的主要數(shù)據(jù)來(lái)源,其中相當(dāng)一部分(約 80-90%)示例的長(zhǎng)度都不超過(guò) 2K 個(gè)詞元。這一結(jié)果表明,僅將上下文窗口擴(kuò)展到 8-32K 可能不會(huì)帶來(lái)顯著的性能提升。在預(yù)訓(xùn)練期間,我們通常將多個(gè)輸入示例組合成一個(gè)序列,直至達(dá)到最大的上下文長(zhǎng)度。如果兩個(gè)拼接訓(xùn)練示例之間沒(méi)有關(guān)聯(lián),我們就在那些不需要彼此通信的詞元上浪費(fèi)了注意力機(jī)制的計(jì)算開(kāi)銷。 換句話說(shuō),盡管我們看到使用 16-32K 上下文窗口進(jìn)行訓(xùn)練的計(jì)算開(kāi)銷對(duì)于當(dāng)前模型大小來(lái)說(shuō)是可行的,但在預(yù)訓(xùn)練期間,我們尚未找到可有效利用這個(gè)更大的上下文窗口的方法。 3.2 如何創(chuàng)建有意義的長(zhǎng)文本預(yù)訓(xùn)練數(shù)據(jù)? 雖然其他來(lái)源(如書籍和科學(xué)文章)能夠提供比 CommonCrawl 和 Github 更長(zhǎng)的上下文,但這些數(shù)據(jù)是否包含足夠的廣度和多樣性來(lái)訓(xùn)練高性能的 LLM 仍然存疑。在這種情況下,一種選擇是,尋找更多樣化的長(zhǎng)上下文數(shù)據(jù)來(lái)源,例如通過(guò)出版社獲得其他教科書或教程的許可。此外,我認(rèn)為利用數(shù)據(jù)源的元數(shù)據(jù)(結(jié)構(gòu))可能是另一個(gè)可行途徑:
3.3 是否可以在訓(xùn)練過(guò)程中使用可變的序列長(zhǎng)度? 不同于將訓(xùn)練分為兩個(gè)階段(即短序列的預(yù)訓(xùn)練階段和長(zhǎng)序列的微調(diào)階段),我們也可以使用多個(gè)序列長(zhǎng)度進(jìn)行訓(xùn)練。具體而言,我們可以將預(yù)訓(xùn)練數(shù)據(jù)劃分為不同的 bucket(如小于2K,小于 16K 等),并根據(jù)每批(或每 X 批)數(shù)據(jù)調(diào)整上下文長(zhǎng)度。這樣,我們只需在具有長(zhǎng)上下文的文件上承擔(dān)注意力計(jì)算開(kāi)銷。當(dāng)然,目前尚不清楚這種方法是否比兩階段訓(xùn)練過(guò)程更加有效。 3.4 如何評(píng)估長(zhǎng)上下文能力? 缺乏合適的基準(zhǔn)測(cè)試也許是評(píng)估長(zhǎng)上下文能力的一個(gè)主要障礙。雖然可以通過(guò)一些用例來(lái)進(jìn)行測(cè)試,如倉(cāng)庫(kù)級(jí)代碼補(bǔ)全或?qū)﹂L(zhǎng)篇財(cái)務(wù)報(bào)告或法律合同進(jìn)行問(wèn)答和摘要,但我們尚未建立針對(duì)這些應(yīng)用程序的良好基準(zhǔn)測(cè)試。此外,正如 CodeLLaMA 論文所指出的,研究人員采用了一些代理任務(wù)(proxy task)來(lái)測(cè)量長(zhǎng)代碼文件的困惑度(perplexity)或合成的上下文檢索任務(wù)(synthetic in-context retrieval task)的性能。 雖然在缺乏適當(dāng)評(píng)估基準(zhǔn)的情況下,我們無(wú)法準(zhǔn)確評(píng)估新的長(zhǎng)上下文語(yǔ)言模型的有效性。但我相信,隨著時(shí)間的推移,研究界和開(kāi)源社區(qū)將解決此評(píng)估問(wèn)題。目前,我所提出的擴(kuò)展上下文長(zhǎng)度的建議是否有效尚不確定,但我希望通過(guò)以上分析,能幫助讀者更好地理解上下文長(zhǎng)度、計(jì)算開(kāi)銷和(預(yù))訓(xùn)練數(shù)據(jù)之間的權(quán)衡。 4局限性
附錄:推導(dǎo) Transformer 的 FLOPs Transformer 在我們開(kāi)始計(jì)算 FLOPs 之前,需要定義 Transformer 模型中的運(yùn)算。此處我們只關(guān)注Transformer 層,排除了詞元嵌入、位置編碼和輸出層,對(duì)于大型模型來(lái)說(shuō),這些部分的影響很小。因此,我們從嵌入
MatMul FLOPs 了解模型執(zhí)行前向和后向傳播所需的浮點(diǎn)運(yùn)算數(shù)量(FLOPs)是非常重要的背景信息。下文詳細(xì)介紹了最耗費(fèi) FLOPs 的操作:矩陣乘法。 參照矩陣乘法的數(shù)學(xué)公式
Transformer 的 FLOPs 數(shù)量 下面是 Transformer 層中不同部分所需的 FLOPs 數(shù)量。只考慮矩陣乘法,不包括層歸一化、GeLU 激活和殘差連接等逐元素操作,也不考慮執(zhí)行優(yōu)化 step 所需的 FLOPs 數(shù)。 FFN FLOPs
QKVO FLOPs
注意力 FLOPs
單個(gè)詞元的 FLOPs
正如下面將要討論的,因?yàn)槲覀儧](méi)有考慮語(yǔ)言模型的自回歸特性,所以這實(shí)際上高估了注意力 FLOPs。 注意力 FLOPs 被高估了 請(qǐng)注意,對(duì)于自回歸解碼器模型而言,詞元只會(huì)關(guān)注先前的詞元序列。這意味著注意力分?jǐn)?shù)矩陣S是一個(gè)下三角矩陣,不需要計(jì)算上三角部分。因此,方程10中的計(jì)算僅需要
與 6ND FLOP 的近似關(guān)系 我們很容易就能得到 6ND 這個(gè)近似 Transformer 訓(xùn)練 FLOPs 的公式 。首先,
用于訓(xùn)練的詞元數(shù) D 由 轉(zhuǎn)自:https://blog.csdn.net/OneFlow_Official/article/details/133110112 該文章在 2024/1/27 15:54:24 編輯過(guò) |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開(kāi)發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")



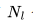 個(gè)Transformer 層、一個(gè)隱藏狀態(tài)維度
個(gè)Transformer 層、一個(gè)隱藏狀態(tài)維度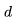 和上下文長(zhǎng)度
和上下文長(zhǎng)度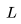 的模型來(lái)說(shuō),每個(gè)詞元的 FLOPs(FLOPs/token)細(xì)分如下:
的模型來(lái)說(shuō),每個(gè)詞元的 FLOPs(FLOPs/token)細(xì)分如下: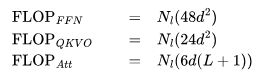
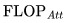 是唯一與上下文長(zhǎng)度
是唯一與上下文長(zhǎng)度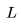 有關(guān)的項(xiàng)。
有關(guān)的項(xiàng)。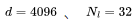 。在每個(gè)柱狀圖頂部,展示了注意力 FLOPs 的相對(duì)貢獻(xiàn):
。在每個(gè)柱狀圖頂部,展示了注意力 FLOPs 的相對(duì)貢獻(xiàn):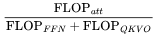 。
。
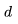 的平方成正比。對(duì)于 LLaMA-65B(
的平方成正比。對(duì)于 LLaMA-65B(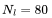 ),維度
),維度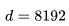 是 LLaMA-7B 大小的兩倍;這意味著,我們可以將上下文長(zhǎng)度增加一倍,而計(jì)算開(kāi)銷保持不變!換句話說(shuō),與使用 16-32K 的上下文窗口產(chǎn)生的開(kāi)銷相同,都在 16-33% 范圍內(nèi)。
是 LLaMA-7B 大小的兩倍;這意味著,我們可以將上下文長(zhǎng)度增加一倍,而計(jì)算開(kāi)銷保持不變!換句話說(shuō),與使用 16-32K 的上下文窗口產(chǎn)生的開(kāi)銷相同,都在 16-33% 范圍內(nèi)。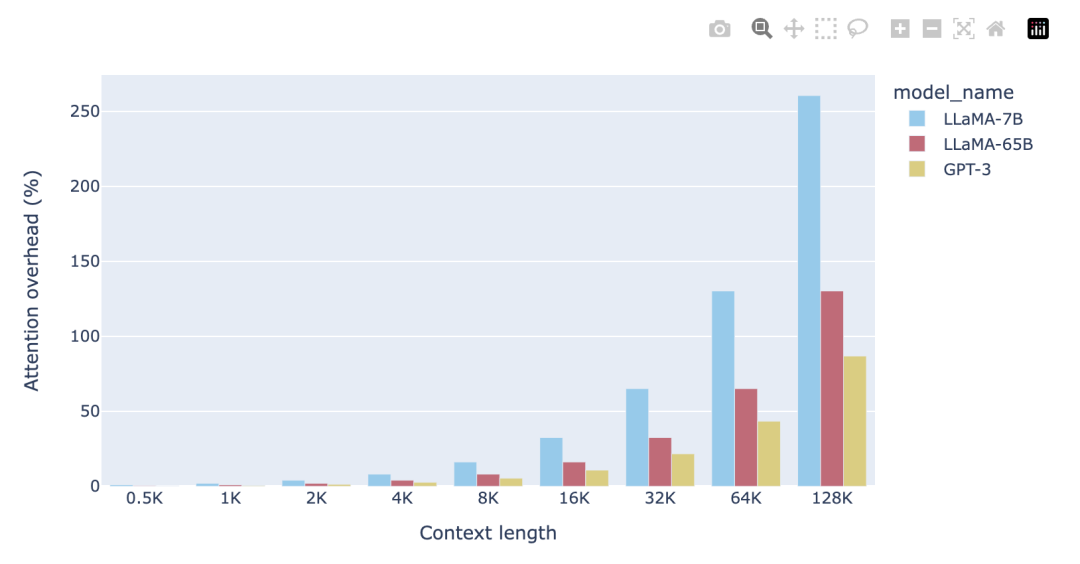
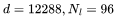 )等更大的模型,可以將上下文窗口增加到 64K,并產(chǎn)生幾乎相同的計(jì)算開(kāi)銷(40%)。盡管我們不確定是否需要如此大的模型,詳情請(qǐng)參見(jiàn)之前的文章。
)等更大的模型,可以將上下文窗口增加到 64K,并產(chǎn)生幾乎相同的計(jì)算開(kāi)銷(40%)。盡管我們不確定是否需要如此大的模型,詳情請(qǐng)參見(jiàn)之前的文章。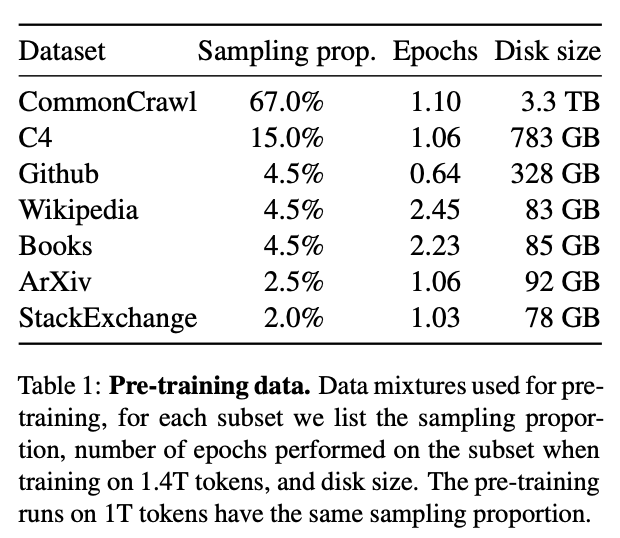
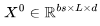 開(kāi)始,然后通過(guò) J 個(gè) Transformer 層進(jìn)行傳遞——參見(jiàn)下圖中的定義。需要注意的是,許多運(yùn)算都是批量矩陣乘法,其中權(quán)重矩陣在第一個(gè)維度(bs)被廣播。
開(kāi)始,然后通過(guò) J 個(gè) Transformer 層進(jìn)行傳遞——參見(jiàn)下圖中的定義。需要注意的是,許多運(yùn)算都是批量矩陣乘法,其中權(quán)重矩陣在第一個(gè)維度(bs)被廣播。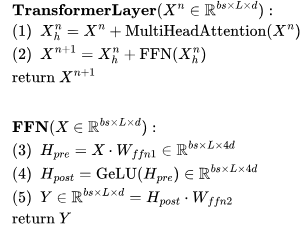

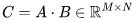 ,其中有輸入矩陣
,其中有輸入矩陣 和
和 。得到的矩陣
。得到的矩陣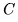 包含
包含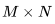 個(gè)元素, 每個(gè)元素通過(guò)對(duì) K 個(gè)元素(element)進(jìn)行點(diǎn)積而得到。因此,我們需要
個(gè)元素, 每個(gè)元素通過(guò)對(duì) K 個(gè)元素(element)進(jìn)行點(diǎn)積而得到。因此,我們需要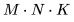 個(gè)運(yùn)算來(lái)計(jì)算矩陣乘法,其中每個(gè)運(yùn)算都涉及乘法和加法,因此總的 FLOPs 數(shù)量是
個(gè)運(yùn)算來(lái)計(jì)算矩陣乘法,其中每個(gè)運(yùn)算都涉及乘法和加法,因此總的 FLOPs 數(shù)量是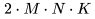 ,詳情可參考 Nvidia 的文檔(https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html)。
,詳情可參考 Nvidia 的文檔(https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html)。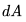 和
和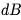 。根據(jù) CS231n 的講座筆記,它們的計(jì)算公式如下:
。根據(jù) CS231n 的講座筆記,它們的計(jì)算公式如下: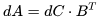 . 因?yàn)?img src="/files/attmgn/2024/1/freeflydom20240127155127723_37.jpg" style="max-width:640px;margin:6px;border:0px solid #FFFFFF;border-radius:5px;border-collapse:collapse;background-color:#FFFFFF;" onmousewheel="return bbimg(this)"/>和
. 因?yàn)?img src="/files/attmgn/2024/1/freeflydom20240127155127723_37.jpg" style="max-width:640px;margin:6px;border:0px solid #FFFFFF;border-radius:5px;border-collapse:collapse;background-color:#FFFFFF;" onmousewheel="return bbimg(this)"/>和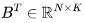 ,有
,有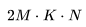 FLOPs。
FLOPs。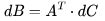 . 因?yàn)?img src="/files/attmgn/2024/1/freeflydom20240127155127953_41.jpg" style="max-width:640px;margin:6px;border:0px solid #FFFFFF;border-radius:5px;border-collapse:collapse;background-color:#FFFFFF;" onmousewheel="return bbimg(this)"/>和
. 因?yàn)?img src="/files/attmgn/2024/1/freeflydom20240127155127953_41.jpg" style="max-width:640px;margin:6px;border:0px solid #FFFFFF;border-radius:5px;border-collapse:collapse;background-color:#FFFFFF;" onmousewheel="return bbimg(this)"/>和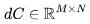 ,有
,有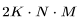 FLOPs。
FLOPs。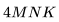 ,
,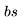 乘以
乘以 。
。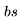 乘以
乘以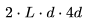 。
。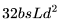 。
。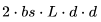 個(gè) FLOPs。
個(gè) FLOPs。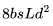 ,后向傳播的 FLOPs 數(shù)為
,后向傳播的 FLOPs 數(shù)為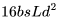
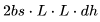 FLOPs。
FLOPs。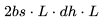 FLOPs。
FLOPs。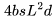 ,用于前向傳播,而后向傳播需要的 FLOPs 為
,用于前向傳播,而后向傳播需要的 FLOPs 為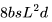 。
。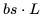 。此外,我們已經(jīng)計(jì)算了單個(gè) Transformer 層的 FLOPs,并且需要乘以
。此外,我們已經(jīng)計(jì)算了單個(gè) Transformer 層的 FLOPs,并且需要乘以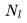 來(lái)得到總的 FLOPs。這得出以下三項(xiàng):
來(lái)得到總的 FLOPs。這得出以下三項(xiàng):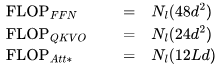
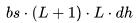 個(gè) FLOPs。類似地,在注意力輸出計(jì)算中(方程12),矩陣P是一個(gè)下三角矩陣,因此 FLOPs 減少至
個(gè) FLOPs。類似地,在注意力輸出計(jì)算中(方程12),矩陣P是一個(gè)下三角矩陣,因此 FLOPs 減少至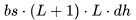 。每個(gè)詞元總的注意力 FLOPs 為:
。每個(gè)詞元總的注意力 FLOPs 為: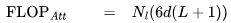
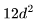 給出了Transformer 層的參數(shù)數(shù)量。因此,總的參數(shù)數(shù)量N與 FLOPs/token 之間的關(guān)系如下:
給出了Transformer 層的參數(shù)數(shù)量。因此,總的參數(shù)數(shù)量N與 FLOPs/token 之間的關(guān)系如下: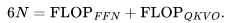
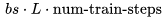 得到。值得注意的是,這個(gè)近似忽略了
得到。值得注意的是,這個(gè)近似忽略了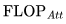 。正如我們所見(jiàn),對(duì)于 2K 上下文窗口,該項(xiàng)很小,但對(duì)于更長(zhǎng)的上下文窗口,它開(kāi)始占主導(dǎo)地位。
。正如我們所見(jiàn),對(duì)于 2K 上下文窗口,該項(xiàng)很小,但對(duì)于更長(zhǎng)的上下文窗口,它開(kāi)始占主導(dǎo)地位。