前言
真沒想到,距離視頻生成上一輪的集中爆發(詳見《Sora之前的視頻生成發展史:從Gen2、Emu Video到PixelDance、SVD、Pika 1.0》)才過去三個月,沒想OpenAI一出手,該領域又直接變天了
自打2.16日OpenAI發布sora以來(其開發團隊包括DALLE 3的4作Tim Brooks、DiT一作Bill Peebles、三代DALLE的核心作者之一Aditya Ramesh等13人),不但把同時段Google發布的Gemini 1.5干沒了聲音,而且網上各個渠道,大量新聞媒體、自媒體(含公號、微博、博客、視頻)做了大量的解讀,也引發了圈內外的大量關注
很多人因此認為,視頻生成領域自此進入了大規模應用前夕,好比NLP領域中GPT3的發布
一開始,我還自以為視頻生成這玩意對于有場景的人,是重大利好,比如在影視行業的
對于沒場景的人,只能當熱鬧看看,而且我司大模型項目開發團隊去年年底還考慮過是否做視頻生成的應用,但當時想了好久,沒找到場景,做別的應用去了
可當我接連扒出sora相關的10多篇論文之后,覺得sora和此前發布的視頻生成模型有了質的飛躍(不只是一個60s),而是再次印證了大力出奇跡,大模型似乎可以在力大磚飛的情況下開始理解物理世界了,使得我司大模型項目組也愿意重新考慮開發視頻生成的相關應用
本文主要分為三個部分(初步理解只看第一部分即可,深入理解看第二部分,更多細節則看第三部分)
第一部分,側重sora的核心技術解讀
方便大家把握重點,且會比一切新聞稿都更準確,此外
 如果之前沒有了解過DDPM、ViT的,建議先閱讀下此文《從VAE、擴散模型DDPM、DETR到ViT、Swin transformer》
如果之前沒有了解過DDPM、ViT的,建議先閱讀下此文《從VAE、擴散模型DDPM、DETR到ViT、Swin transformer》
如果之前沒有了解過圖像生成的,建議先閱讀下此文《從CLIP到DALLE1/2、DALLE 3、Stable Diffusion、SDXL Turbo、LCM》
當然,如果個別朋友實在不想點開看上面的兩篇文章,我也盡可能在本文中把相關重點交代清楚
第二部分,側重sora相關技術的發展演變
把sora涉及到的關鍵技術在本文中全部全面、深入、細致的闡述清楚,畢竟如果人云亦云就不用我來寫了
且看完這部分你會發現,從來沒有任何一個火爆全球的產品是一蹴而就的,且基本都是各種創新技術的集大成者(Google很多工作把transformer等各路技術發揚光大,但OpenAI則把各路技術 整合到極致了..)
第三部分,根據sora的32個reference以窺探其背后的更多細節
由于sora實在是太火了,網上各種解讀非常多,有的很專業,有的看上去一本正經 實則是胡說八道(即便他的title看起來有一定的水平),為方便大家辨別什么樣的解讀是不對的,特把一些更深入的細節也介紹下
第一部分 OpenAI Sora的關鍵技術點
1.1 Sora的三大Transformer組件
1.1.1 從前置工作DALLE 2到sora的三大組件
為方便大家更好的理解sora背后的原理,我們先來快速回顧下AI繪畫的原理(理解了AI繪畫,也就理解了sora一半)
以DALLE 2為例,如下圖所示(以下內容來自此文:從CLIP到DALLE1/2、DALLE 3、Stable Diffusion、SDXL Turbo、LCM)
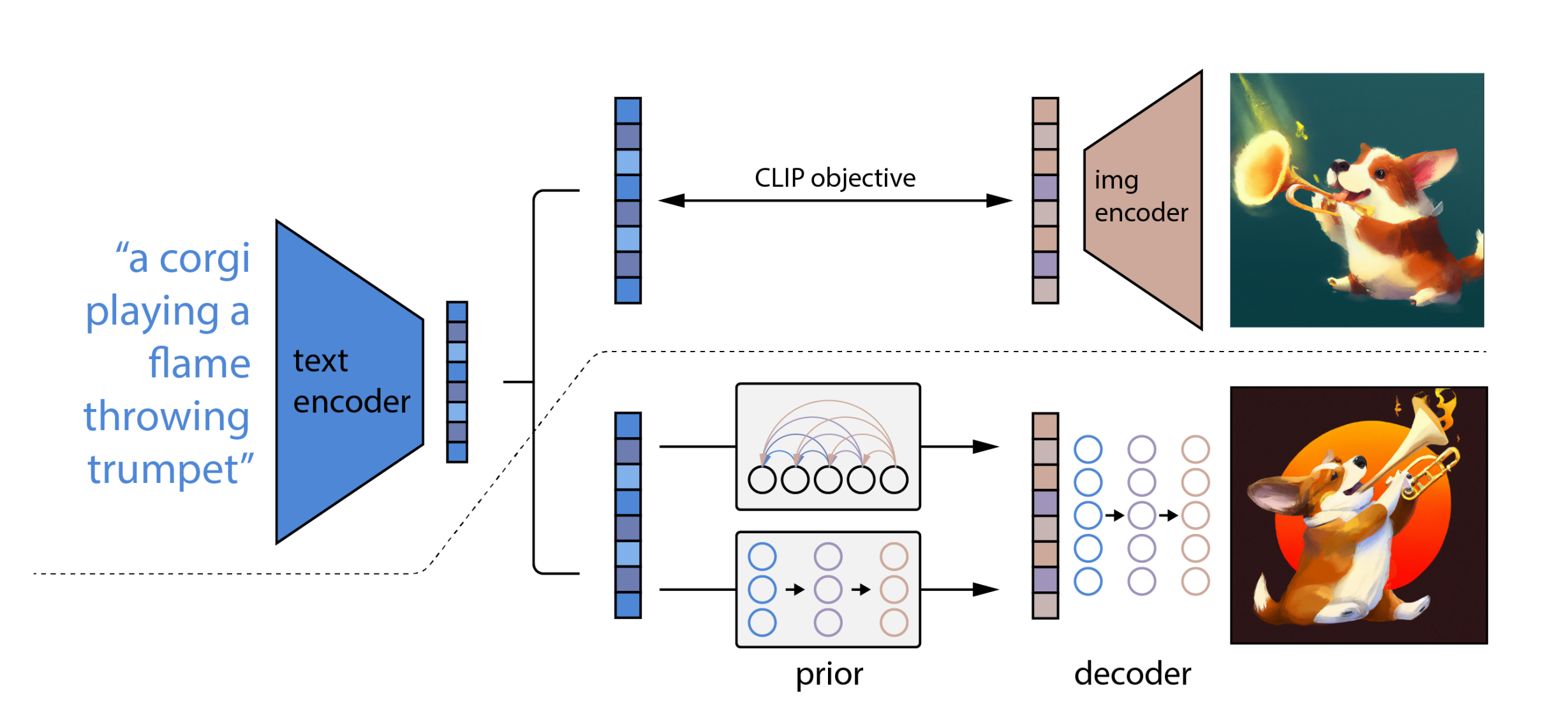
CLIP訓練過程:學習文字與圖片的對應關系
如上圖所示,CLIP的輸入是一對對配對好的的圖片-文本對(根據對應文本一條狗,去匹配一條狗的圖片),這些文本和圖片分別通過Text Encoder和Image Encoder輸出對應的特征,然后在這些輸出的文字特征和圖片特征上進行對比學習
DALL·E2:prior + decoder
上面的CLIP訓練好之后,就將其凍住了,不再參與任何訓練和微調,DALL·E2訓練時,輸入也是文本-圖像對,下面就是DALL·E2的兩階段訓練:
階段一 prior的訓練:根據文本特征(即CLIP text encoder編碼后得到的文本特征),預測圖像特征(CLIP image encoder編碼后得到的圖片特征)
換言之,prior模型的輸入就是上面CLIP編碼的文本特征,然后利用文本特征預測圖片特征(說明白點,即圖中右側下半部分預測的圖片特征的ground truth,就是圖中右側上半部分經過CLIP編碼的圖片特征),就完成了prior的訓練
推理時,文本還是通過CLIP text encoder得到文本特征,然后根據訓練好的prior得到類似CLIP生成的圖片特征,此時圖片特征應該訓練的非常好,不僅可以用來生成圖像,而且和文本聯系的非常緊(包含豐富的語義信息)
階段二 decoder生成圖:常規的擴散模型解碼器,解碼生成圖像
這里的decoder就是升級版的GLIDE(GLIDE基于擴散模型),所以說DALL·E2 = CLIP + GLIDE
所以對于DALLE 2來說,正因為經過了大量上面這種訓練,所以便可以根據人類給定的prompt畫出人類預期的畫作,說白了,可以根據text預測畫作長什么樣
最終,sora由三大Transformer組件組成(如果你還不了解transformer或注意力機制,請讀此文):Visual Encoder(即Video transformer,類似下文將介紹的ViViT)、Diffusion Transformer、Transformer Decoder,具體而言
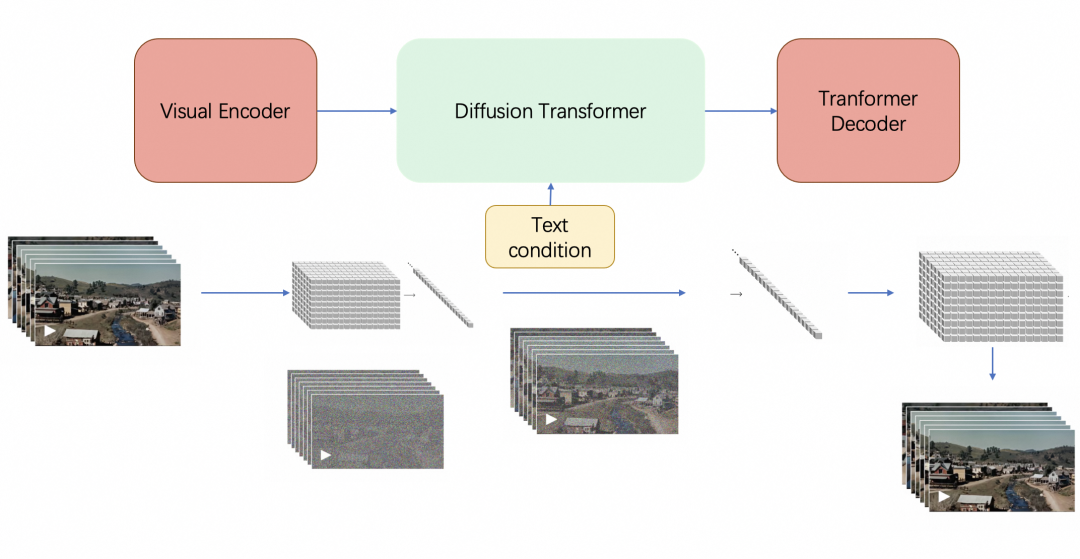
訓練中,給定一個原始視頻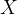
Visual Encoder將視頻壓縮到較低維的潛在空間(潛在空間這個概念在stable diffusion中用的可謂爐火純青了,詳見此文的第三部分)
然后把視頻分解為在時間和空間上壓縮的潛在表示(不重疊的3D patches),即所謂的一系列時空Patches
再將這些patches拉平成一個token序列,這個token序列其實就是原始視頻的表征:visual token序列
Sora 在這個壓縮的潛在空間中接受訓練,還是類似擴散模型那一套,先加噪、再去噪
這里,有兩點必須注意的是
1 擴散時卷積結構U-net被替換成了transformer結構的DiT(加之視覺元素轉換成token之后,transformer擅長長距離建模,下文詳述DiT)
2 視頻中這一系列幀在上個過程中是同時被編碼的,去噪也是一系列幀并行去噪的(每一幀逐步去噪、多幀并行去噪)
此外,去噪過程中,可以加入去噪的條件(即text condition),這個去噪條件可以是原始視頻的描述,也可以是二次創作的prompt
比如可以將visual tokens視為query,將text tokens作為key和value,然后類似SD那樣做cross attention
OpenAI 還訓練了相應的Transformer解碼器模型,將生成的潛在表示映射回像素空間,從而生成視頻
你會發現,上述整個過程,其實和SD的原理是有較大的相似性(SD原理詳見此文《從CLIP到DALLE1/2、DALLE 3、Stable Diffusion、SDXL Turbo、LCM》的3.2節),當然,不同之處也有很多,比如視頻需要一次性還原多幀、圖像只需要還原一幀
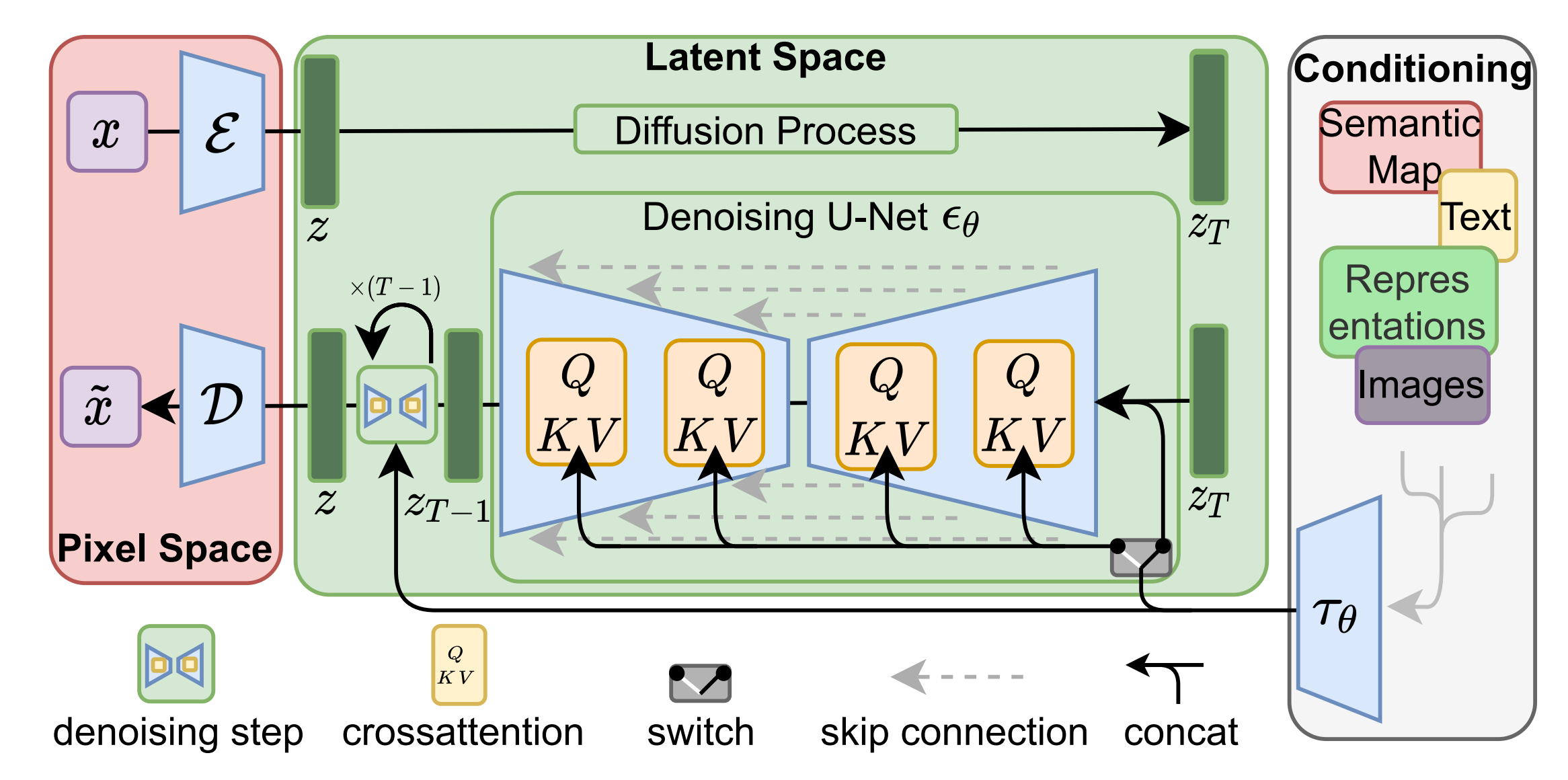
網上也有不少人畫出了sora的架構圖,比如來自魔搭社區的

1.1.2 如何理解所謂的時空編碼(含其好處)
首先,一個視頻無非就是沿著時間軸分布的圖像序列而已

但其中有個問題是,因為像素的關系,一張圖像有著比較大的維度(比如250 x 250),即一張圖片上可能有著5萬多個元素,如果根據上一張圖片的5萬多元素去逐一交互下一張圖片的5萬多個元素,未免工程過于浩大(而且,即便是同一張圖片上的5萬多個像素點之間兩兩做self-attention,你都會發現計算復雜度超級高)
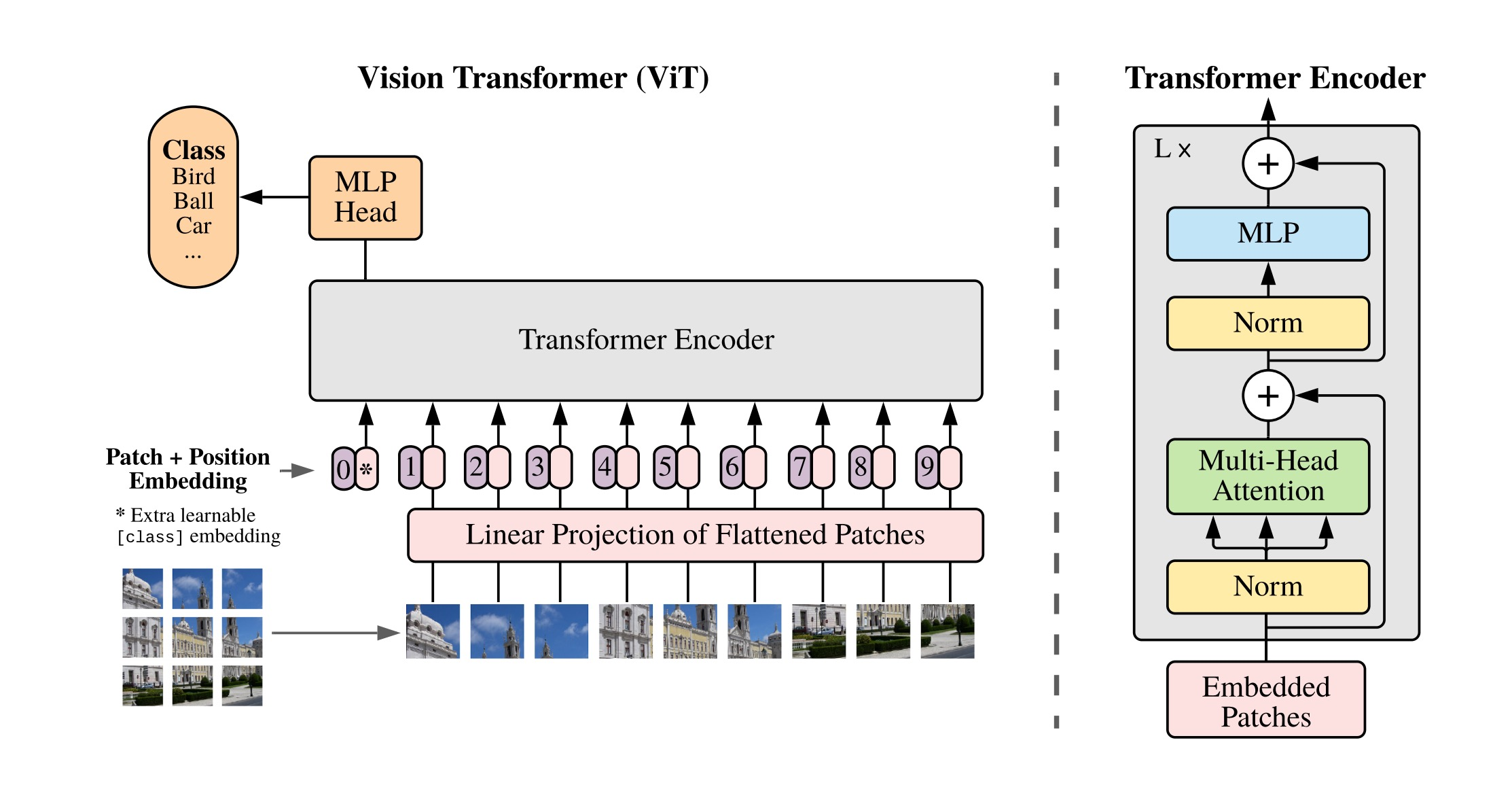
故為降低處理的復雜度,可以類似ViT把一張圖像劃分為九宮格(如下圖的左下角),如此,處理9個圖像塊總比一次性處理250 x 250個像素維度 要好不少吧(ViT的出現直接挑戰了此前CNN在視覺領域長達近10年的絕對統治地位,其原理細節詳見本文開頭提到的此文第4部分)
當我們理解了一張靜態圖像的patch表示之后(不管是九宮格,還是16 x 9個格),再來理解所謂的時空Patches就簡單多了,無非就是在縱向上加上時間的維度,比如t1 t2 t3 t4 t5 t6
而一個時空patch可能跨3個時間維度,當然,也可能跨5個時間維度

如此,同時間段內不同位置的立方塊可以做橫向注意力交互——空間編碼
不同時間段內相同位置的立方塊則可以做縱向注意力交互——時間編碼
(如果依然還沒有特別理解,沒關系,可以再看下下文第二部分中對ViViT的介紹)

可能有同學問,這么做有什么好處呢?好處太多了
總之,基于 patches 的表示,使 Sora 能夠對不同分辨率、持續時間和長寬比的視頻和圖像進行訓練。在推理時,也可以可以通過在適當大小的網格中排列隨機初始化的 patches 來控制生成視頻的大小
DiT 作者之一 Saining Xie 在推文中提到:Sora“可能還使用了谷歌的 Patch n’ Pack (NaViT) 論文成果,使其能夠適應可變的分辨率/持續時間/長寬比”
當然,ViT本身也能夠處理任意分辨率(不同分辨率相當于不同長度的圖片塊序列),但NaViT提供了一種高效訓練的方法,關于NaViT的更多細節詳見下文的介紹
而過去的圖像和視頻生成方法通常需要調整大小、進行裁剪或者是將視頻剪切到標準尺寸,例如 4 秒的視頻分辨率為 256x256。相反,該研究發現在原始大小的數據上進行訓練,最終提供以下好處:
首先是采樣的靈活性:Sora 可以采樣寬屏視頻 1920x1080p,垂直視頻 1920x1080p 以及兩者之間的視頻。這使 Sora 可以直接以其天然縱橫比為不同設備創建內容。Sora 還允許在生成全分辨率的內容之前,以較小的尺寸快速創建內容原型 —— 所有內容都使用相同的模型

其次使用視頻的原始長寬比進行訓練可以提升內容組成和幀的質量
其他模型一般將所有訓練視頻裁剪成正方形,而經過正方形裁剪訓練的模型生成的視頻(如下圖左側),其中的視頻主題只是部分可見;相比之下,Sora 生成的視頻具有改進的幀內容(如下圖右側)

1.1.3 Diffusion Transformer(DiT):擴散過程中以Transformer為骨干網絡
sora不是第一個把擴散模型和transformer結合起來用的模型,但是第一個取得巨大成功的,為何說它是結合體呢
一方面,它類似擴散模型那一套流程,給定輸入噪聲patches(以及文本提示等調節信息),訓練出的模型來預測原始的不帶噪聲的patches「Sora is a diffusion model, given input noisy patches (and conditioning information like text prompts), it’s trained to predict the original “clean” patches」
類似把一張圖片打上各種馬賽克,然后訓練一個模型,讓它學會去除各種馬賽克,且一開始各種失敗沒關系,反正有原圖作為ground truth,不斷縮小與原圖之間的差異即可
而當把圖片打上全部馬賽克之后,還可以訓練該模型根據prompt直接創作的能力,讓它畫啥就畫啥
更多細節的理解請參看此文《從VAE、擴散模型DDPM、DETR到ViT、Swin transformer》
二方面,它把圖像打散成塊后,計算塊與塊之間的注意力,而這套自注意力機制便是transformer的機制

總之,總的來說,Sora是一個在不同時長、分辨率和寬高比的視頻及圖像上訓練而成的擴散模型,同時采用了Transformer架構,如sora官博所說,Sora is a diffusion transformer,簡稱DiT
關于DiT的更多細節詳見下文第二部分介紹的DiT
1.2 基于DALLE 3的重字幕技術:提升文本-視頻數據質量
1.2.1 DALLE 3的重字幕技術:為文本-視頻數據集打上詳細字幕
首先,訓練文本到視頻生成系統需要大量帶有相應文本字幕的視頻,研究團隊將 DALL?E 3 中的重字幕(re-captioning)技術應用于視頻
具體來說,研究團隊首先訓練一個高度描述性的字幕生成器模型,然后使用它為訓練集中所有視頻生成文本字幕
與DALLE 3類似,研究團隊還利用 GPT 將簡短的用戶 prompt 轉換為較長的詳細字幕,然后發送到視頻模型,這使得 Sora 能夠生成準確遵循用戶 prompt 的高質量視頻
關于DALLE 3的重字幕技術更具體的細節請見此文2.3節《AI繪畫原理解析:從CLIP到DALLE1/2、DALLE 3、Stable Diffusion、SDXL Turbo、LCM》
2.3 DALLE 3:Improving Image Generation with Better Captions
2.3.1 為提高文本圖像配對數據集的質量:基于谷歌的CoCa微調出圖像字幕生成器
2.3.1.1 什么是谷歌的CoCa
2.1.1.2 分別通過短caption、長caption微調預訓練好的image captioner
2.1.1.3 為提高合成caption對文生圖模型的性能:采用描述詳細的長caption,訓練的混合比例高達95%..
1.2.2 類似Google的W.A.L.T工作:引入auto regressive進行視頻擴展
其次,如之前所述,為了保證視頻的一致性,模型層不是通過多個stage方式來進行預測,而是整體預測了整個視頻的latent(即去噪時非先去噪幾幀,再去掉幾幀,而是一次性去掉全部幀的噪聲)
但在視頻內容的擴展上,比如從一段已有的視頻向后拓展出新視頻的訓練過程中可能引入了auto regressive的task,以幫助模型更好的進行視頻特征和幀間關系的學習
更多可以參考Google的W.A.L.T工作,下文將詳述
1.3 對真實物理世界的模擬能力
1.3.1 sora學習了大量關于3D幾何的知識
OpenAI 發現,視頻模型在經過大規模訓練后,會表現出許多有趣的新能力。這些能力使 Sora 能夠模擬物理世界中的人、動物和環境的某些方面。這些特性的出現沒有任何明確的三維、物體等歸納偏差 — 它們純粹是規模現象
三維一致性(下圖左側)
Sora 可以生成動態攝像機運動的視頻。隨著攝像機的移動和旋轉,人物和場景元素在三維空間中的移動是一致的
針對這點,sora一作Tim Brooks說道,sora學習了大量關于3D幾何的知識,但是我們并沒有事先設定這些,它完全是從大量數據中學習到的


長序列連貫性和目標持久性(上圖右側)
視頻生成系統面臨的一個重大挑戰是在對長視頻進行采樣時保持時間一致性
例如,即使人、動物和物體被遮擋或離開畫面,Sora 模型也能保持它們的存在。同樣,它還能在單個樣本中生成同一角色的多個鏡頭,并在整個視頻中保持其外觀
與世界互動(下圖左側)
Sora 有時可以模擬以簡單方式影響世界狀態的動作。例如,畫家可以在畫布上留下新的筆觸,這些筆觸會隨著時間的推移而持續,而視頻中一個人咬一口面包 則面包上會有一個被咬的缺口


模擬數字世界(上圖右側)
視頻游戲就是一個例子。Sora 可以通過基本策略同時控制 Minecraft 中的玩家,同時高保真地呈現世界及其動態。只需在 Sora 的提示字幕中提及 「Minecraft」,就能零樣本激發這些功能
1.3.2 sora真的會模擬真實物理世界了么
對于“sora真的會模擬真實物理世界”這個問題,網上的解讀非常多,很多人說sora是通向通用AGI的必經之路、不只是一個視頻生成,更是模擬真實物理世界的模擬器,這個事 我個人覺得從技術的客觀角度去探討更合適,那樣會讓咱們的思維、認知更冷靜,而非人云亦云、最終不知所云
首先,作為“物理世界的模擬器”,需要能夠在虛擬環境中重現物理現實,為用戶提供一個逼真且不違反「物理規律」的數字世界
比如蘋果不能突然在空中漂浮,這不符合牛頓的萬有引力定律;比如在光線照射下,物體產生的陰影和高光的分布要符合光影規律等;比如物體之間產生碰撞后會破碎或者彈開
其次,李志飛等人在《為什么說 Sora 是世界的模擬器?》一文中提到,技術上至少有兩種方式可以實現這樣的模擬器
虛幻引擎(Unreal Engine,UE)就是這種物理世界的模擬器
它內置了光照、碰撞、動畫、剛體、材質、音頻、光電等各種數學模型。一個開發者只需要提供人、物、場景、交互、劇情等配置,系統就能做出一個交互式的游戲,這種交互式的游戲可以看成是一個交互式的動態視頻
UE 這類渲染引擎所創造的游戲世界已經能夠在某種程度上模擬物理世界,只不過它是通過人工數學建模及渲染而成,而非通過模型從數據中自我學習。而且,它也沒有和語言代表的認知模型連接起來,因此本質上缺乏世界常識。而 Sora 代表的AI系統有可能避免這些缺陷和局限
不同于 UE 這一類渲染引擎,Sora 并沒有顯式地對物理規律背后的數學公式去“硬編碼”,而是通過對互聯網上的海量視頻數據進行自監督學習,從而能夠在給定一段文字描述的條件下生成不違反物理世界規律的長視頻
與 UE 這一類“硬編碼”的物理渲染引擎不同,Sora 視頻創作的想象力來自于它端到端的數據驅動,以及跟LLM這類認知模型的無縫結合(比如ChatGPT已經確定了基本的物理常識)
最后值得一提的是,Sora 的訓練可能用了 UE 合成的數據,但 Sora 模型本身應該沒有調用 UE 的能力
更多內容請前往CSDN查看原帖 https://blog.csdn.net/v_JULY_v/article/details/136143475
該文章在 2024/2/24 14:50:00 編輯過






 400 186 1886
400 186 1886


