[點晴永久免費OA]我們能從阿里云史詩級故障中學到什么
當前位置:點晴教程→點晴OA辦公管理信息系統
→『 經驗分享&問題答疑 』
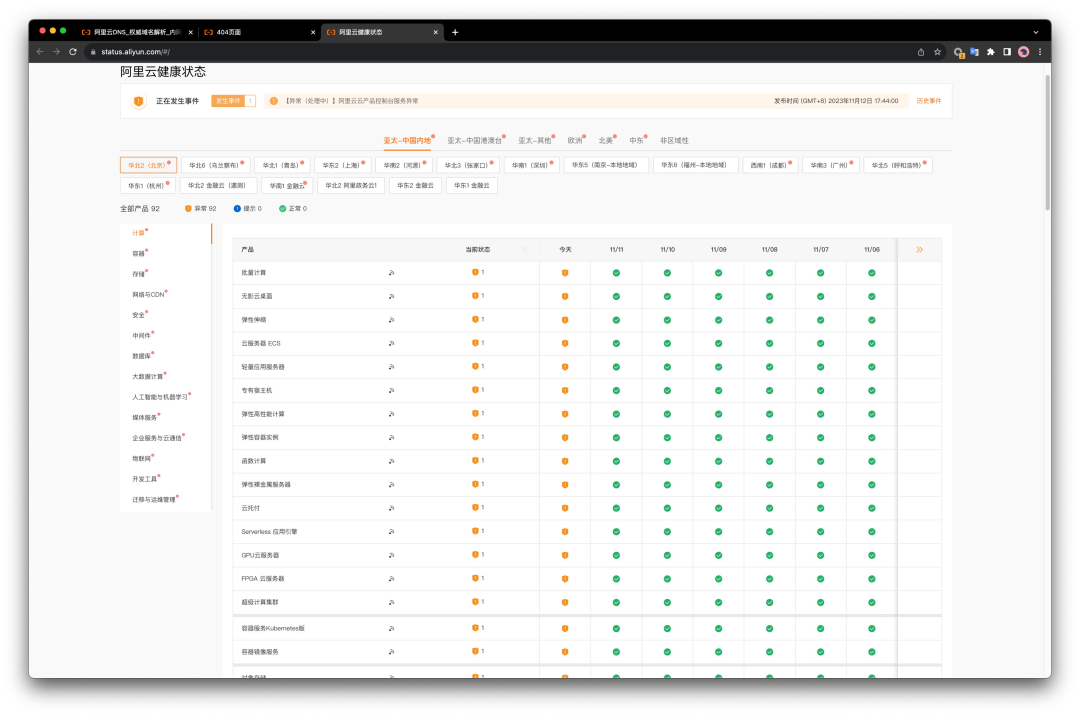
時隔一年阿里云又出大故障,并創造了云計算行業聞所未聞的新記錄 —— 全球所有區域/所有服務同時異常。我們應當如何看待這一史詩級故障案例,以及,能從中學習到什么經驗與教訓?事實是什么?11月12日,也就是雙十一后的第一天,阿里云發生了一場史詩級大翻車。根據阿里云官方的服務狀態頁[1],全球范圍內所有可用區 x 所有服務全部都出現異常,時間從 17:44 到 21: 11,共計3小時16分鐘。
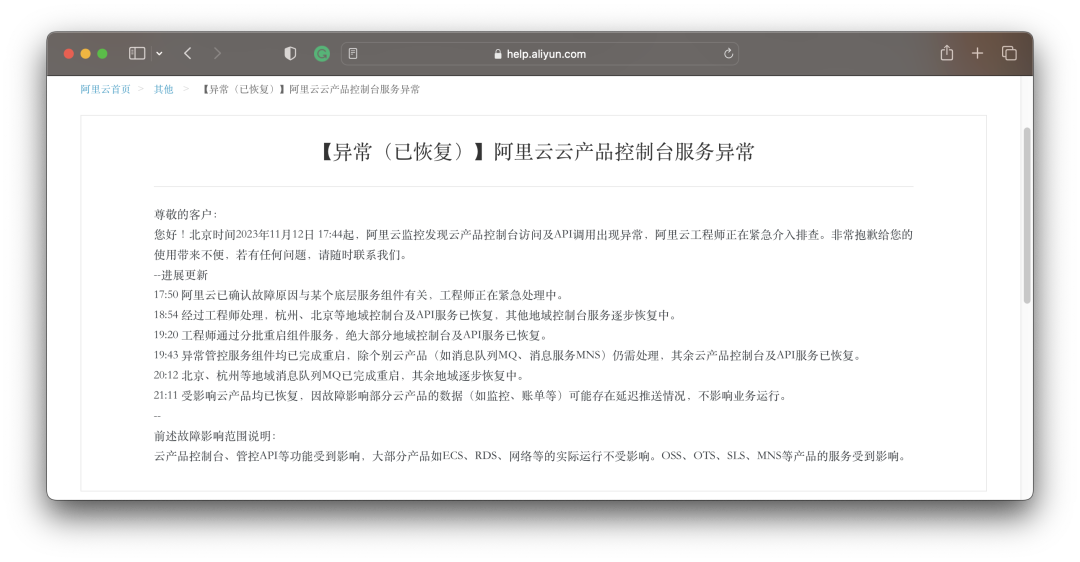
根據阿里云公告[2]稱:“云產品控制臺、管控API等功能受到影響,OSS、OTS、SLS、MNS 等產品的服務受到影響,大部分產品如 ECS、RDS、網絡等的實際運行不受影響”。
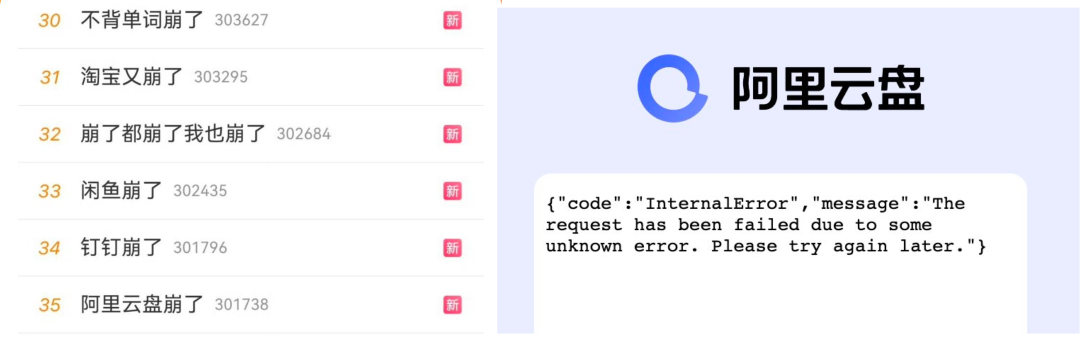
不過大量依賴阿里云服務的應用 APP,包括阿里自己的一系列應用:淘寶,釘釘,閑魚,… 都出現了問題。產生了顯著的外部影響,APP崩了的新聞組團沖上了熱搜。淘寶刷不出聊天圖片,閃送上傳不了接單憑據,充電樁用不了,原神發不出驗證碼,餓了么下不了單,騎手進不了系統,點不了外賣、停車場不抬桿、超市無法結賬。甚至有的學校因此無法用智能公共洗衣機和開水機。無數在周末休息中的研發與運維人員被喊起來加班排障……
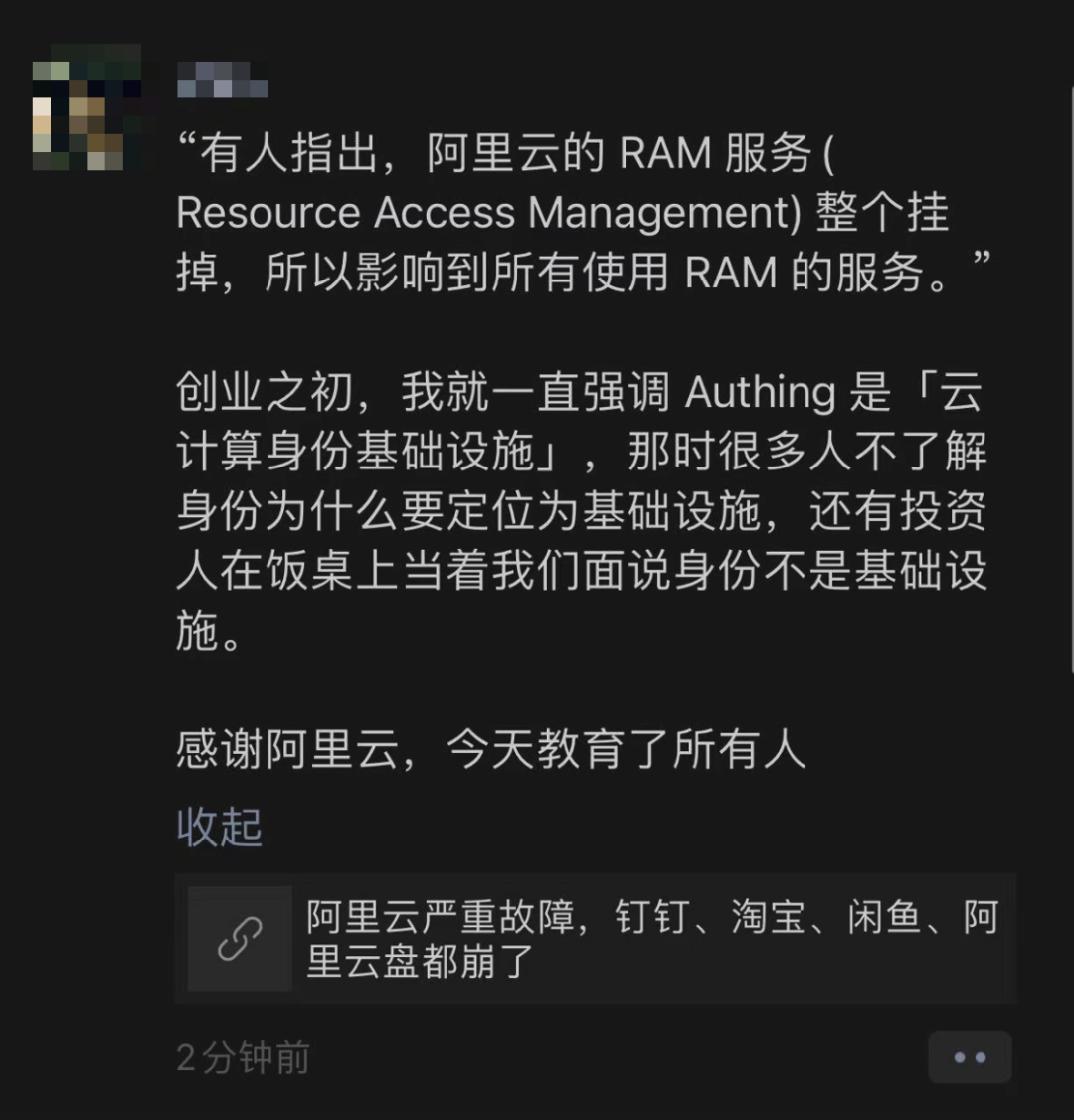
包括金融云,政務云在內的區域也無一幸免。阿里云應該感到萬幸:故障不是發生在雙十一當天,也不在衙門與錢莊的工作時間段,否則大家說不定能上電視看故障復盤了。 原因是什么?盡管阿里云至今仍未給出一份事后故障復盤報告,但老司機根據爆炸半徑,就足以判斷出問題在哪里了 —— 鑒權組件 / Auth 服務。 原因很簡單,能讓全球所有區域同時出問題的肯定不會是機房/硬件故障,而是跨區域共用的云基礎設施組件 —— 要么是認證,要么是計費,極低概率是其他全局性服務。
根因出在認證服務上的可能性最大,因為被管控的資源:類似云服務器 ECS / 云數據庫 RDS 仍然可以繼續運行,用戶只是無法通過控制臺/API對其進行管理操作;然而深度與云API/認證集成的對象存儲 OSS (S3),表格存儲 OTS , SLS,MNS 服務本身可用性直接受到影響。另外一個可以排除的付費服務的現象是:故障期間還有用戶成功付款 薅下了ECS的羊毛。 不僅僅是 OSS,使用其他深度集成 IAM/認證 服務類的云產品也會有這樣的問題,比如 OTS,SLS,MNS 等等。例如,對標 DynamoDB 的 OTS 同樣出現了問題,這是因為 OTS 不像 RDS for PostgreSQL / MySQL 使用數據庫自身認證,而是直接用IAM。 盡管上面的分析過程只是一種推斷,但它與流傳出來的內部消息相吻合:認證掛了導致所有服務異常。至于認證服務本身到底是怎么掛的,在尸檢報告出來前我們也只能猜測:根據各種先例來看,人為配置失誤的可能性最大,比如有小道消息稱:
如果真的是這樣的原因導致認證服務不可用,那可真的是 草臺班子 到家了。盡管聽上去很離譜,但也不算太令人驚奇。再次強調,以上為路邊社消息與合理推論,具體事故原因請以阿里云官方給出的復盤分析報告為準。 影響是什么?像認證這樣的基礎組件一旦出現問題,影響是災難性的。這會導致整個云管控面不可用,傷害會波及到控制臺,API,以及深度依賴云認證基礎設施的服務,比如 OSS、OTS、SLS、MNS。盡管從公告上看來好像只有幾個服務受到影響,但 OSS 這樣的基礎性服務出了問題,帶來的爆炸半徑是難以想象的,絕非“個別服務受到影響” 就能敷衍過去。
對象存儲 OSS (Amazon S3)這樣的服務不同于虛擬機這種資源,是通過云廠商包裝的 HTTP API 對外提供服務的,因此必然深度依賴認證組件:你需要AK/SK / IAM簽名才能使用這些 HTTP API,而認證服務故障將導致這類服務本身不可用。 但是對象存儲 OSS 實在是太重要了,可以說對象存儲是云計算的“定義性服務”,也許是唯一一個在所有云廠商上能達成共識與標準的服務。云廠商的各種“上層”服務或多或少都直接/間接地依賴 OSS,例如 ECS/ RDS 雖然可以運行,但 ECS 快照和 RDS 備份顯然是深度依賴 OSS 的,CDN 回源是依賴 OSS 的,各個服務的日志往往也是寫入 OSS 的。 從現象上看,核心功能跟 OSS 深度綁定的阿里云盤就掛的很慘烈,核心功能跟 OSS 關系不大的服務,比如高德地圖就沒聽說有什么大影響。大部分相關應用的狀態是,主體可以正常打開運行,但是和圖片展示,文件上傳/下載文件這類有關的功能就不可用了。 有一些實踐減輕了對 OSS 的沖擊:比如通常被認為是不安全的 —— 不走認證的 PUBLIC 存儲桶就不受影響;CDN 的使用也緩沖了 OSS 的問題:淘寶商品圖片走 CDN 緩存還可以正常看到,但是買家聊天記錄里實時發送的圖片直接走 OSS 就掛了。 不僅僅是 OSS,使用其他深度集成 IAM/認證 服務類的云產品也會有這樣的問題,比如 OTS,SLS,MNS 等等。例如,對標 DynamoDB 的表格存儲服務 OTS 同樣出現了問題,這是因為 OTS 不像 RDS for PostgreSQL / MySQL 使用數據庫自身的認證機制,而是與云廠商的 Auth 深度綁定。 那么這件事對于阿里云本身會有什么影響呢?首先當然是違反 SLA 產生的賠償,3個半小時的故障范圍,當月可用性指標應當為 99.5%,落在絕大多數服務 SLA 賠償標準的中間檔位上,也就是補償用戶月度服務費用 25%-30% 的代金券。特殊的是這一次故障的區域范圍和服務范圍是全部!
當然阿里云也可以主張說雖然 OSS / OTS 這些服務掛了,但他們的 ECS/RDS 只掛了管控面,不影響正在運行的服務所以不影響 SLA。說起來這種補償即使是真的全部落地也沒幾個錢,更像是一種安撫性的姿態:畢竟和用戶的業務損失比,賠個服務月消 25%代金券簡直就是一種羞辱。 比起用戶信任、技術聲望以及商譽折損而言,賠的那點代金券真的算不上什么。這次事件如果處理不當,很有可能會成為公有云拐點級別的標志性事件。 評論與觀點?馬斯克的推特 X 和 DHH 的 37 Signal 通過下云省下了千萬美元真金白銀,創造了降本增效的“奇跡”,讓下云開始成為一種潮流。云上的用戶在對著賬單猶豫著是否要下云,還沒上云的用戶更是內心糾結是否還要上去。在這樣的背景下,作為本土云領導者的阿里云發生如此重大故障,對于猶豫觀望者的信心無疑是沉重的打擊。恐怕此次故障會成為公有云拐點級別的標志性事件。 阿里云一向以安全穩定高可用自居,上周還剛剛在云棲大會上吹極致穩定性之類的牛逼。但是無數層所謂的的災備,多活,多中心,降級方案,被一次性全部擊穿,打破了N個9神話。如此大范圍、長時間、影響面如此廣的故障,更是創下了云計算行業的歷史記錄。包括金融云和政務云在內(是否是私有化部署的版本?)也同樣出現了服務不可用。 阿里云全球故障揭示出出關鍵基礎設施的巨大風險:完全依托于公有云廠商的大量 Web 服務缺乏基本的自主可控性:在故障發生時除了等死做不了別的事情。同時也展現了壟斷中心化基礎設施的脆弱性:互聯網。這個去中心化的世界奇跡現在主要是在少數幾個大公司/云廠商擁有的計算機上運行。如果 AWS 的主要區域之一出現故障,幾乎一半的互聯網都會隨之下線。某個云廠商本身成為了最大的業務單點,這可不是互聯網設計的初衷! 而這次更為嚴峻的挑戰恐怕還在后面,來自全球用戶的追索賠錢事還小,真正要命的是在各個國家都在強調數據主權的時候,如果因為在中國境內的某個控制中心配置失當導致全球故障的話,(即:你真的卡了別人的脖子)我相信很多海外客戶會立即采取行動,遷移到別的云供應商上:這關乎合規,與可用性無關。 去年十二月阿里云香港機房的故障已經暴露出來了許多的問題,然而一年后沒有不見改進反而來了一個更大的驚喜。這樣的事故對于阿里云的品牌形象絕對是致命打擊,往大了說,像這樣的故障對整個行業的聲譽都有嚴重的損害。阿里云應該盡快給用戶一個解釋與交代,發布詳細的故障復盤報告,講清楚后續改進措施,挽回聲譽與用戶的信任。
畢竟,這種規模的故障,已經不是“殺一個程序員祭天”能解決的事了,得由 CEO 親自出面解決。例如 Cloudflare 月初的管控面故障,CEO 親自出來寫了詳細的事后復盤分析[3]。不幸的是,阿里云經過了幾輪裁員,一年連換了三輪 CEO ,恐怕已經難有能出來扛事接鍋的人了。 能學到什么?往者不可留,逝者不可追,比起哀悼無法挽回的損失,更重要的是從損失中吸取教訓 —— 要是能從別人的損失中吸取教訓那就更好了。所以,我們能從阿里云這場史詩級故障中學到什么? 不要把雞蛋放在同一個籃子里,業務域名解析一定要套一層 CNAME,且 CNAME 域名用不同服務商的解析服務。這個中間層對于阿里云這樣的故障非常重要,用另外一個 DNS 供應商,至少可以給你一個把流量切到別的地方去的選擇,而不是干坐在屏幕前等死,毫無自救能力。 區域優先使用杭州與北京可用區,阿里云故障恢復明顯有優先級,阿里云總部所在地的杭州(華東1)和北京(華北2)故障修復的速度明顯要比其他區域快很多,這兩個區域可以考慮優先使用。雖然同樣都是吃故障,但你可以和阿里自家云上業務享受同種優先待遇了。 謹慎使用需要額外認證的服務:認證鑒權這樣的服務屬于基礎中的基礎,大家都期待它可以始終正常工作。然而越是人們感覺不可能出現故障的東西,真的出現故障時產生的殺傷力就越是毀天滅地。深度使用云廠商提供的 AK/SK/IAM 不僅會讓自己陷入供應商鎖定中,更是將自己暴露在云基礎設施單點的問題里。例如在這次故障中,不使用云廠商認證體系的的 ECS/RDS 本身沒有受到直接沖擊:管控失能無法發起變更,但現有資源仍然可用。 謹慎使用云服務,優先使用純資源。類似 ECS/ESSD 這樣的資源以及單純使用這兩者的 RDS,可以不受管控面故障影響繼續運行。然而 OSS 對象存儲這樣的服務會對云基礎設施有額外的依賴,額外的依賴意味著額外的失效點。只使用基礎云資源的另一個好處是,它們是所有云廠商的提供服務的最大公約數,有利于用戶在不同公有云、以及本地自建中間擇優而選。 不過,很難想象在公有云上卻不用對象存儲 —— 在 ECS 和天價 ESSD 上用 MinIO 自建對象存儲服務并不是真正可行的選項,這涉及到公有云商業模式的核心秘密:廉價S3獲客,天價EBS殺豬。 自建是掌握自己公司命運的最佳手段:如果用戶想真正掌握自己的命運,最終恐怕都會走上下云自建這條路。當年互聯網先輩們平地起高樓創建了這些服務,而現在只會容易的多:純資源云與開源平替的出現讓這件事變得容易太多了。IDC2.0 + 開源自建的組合越來越有競爭力:短路掉公有云這個中間商,直接與 IDC 合作顯然是一個更經濟實惠的選擇。 在當下供過于求的情況下,稍微有點規模的用戶下云省下的錢可以換幾個從大廠出來的資深SRE還能盈余不少。畢竟,自家人出問題你可以進行獎懲激勵督促其改進,但是云出問題能賠給你幾毛錢代金券,又能頂什么用呢? 明確云廠商的 SLA 是營銷工具,而非戰績承諾 在云計算的世界里,服務等級協議(SLA)曾被視為云廠商對其服務質量的承諾。然而,當我們深入研究這些由一堆9組成的 SLA 時,會發現它們并不能像期望的那樣“兜底”:你以為給自己的服務上了保險可以高枕無憂,但其實白花花的銀子買的是提供情緒價值的安慰劑。與其說是 SLA 是對用戶的補償,不如說 SLA 是對云廠商服務質量沒達標時的“懲罰”。 比起會因為故障丟掉獎金與工作的專家工程師來說,SLA的懲罰對于云廠商屬于是自罰三杯,不痛不癢。如果懲罰沒有意義,那么云廠商也沒有動力會提供更好的服務質量。用戶遇到問題時只能提工單等死。所以,SLA 對用戶來說不是兜底損失的保險單。在最壞的情況下,它是堵死了實質性追索的啞巴虧。在最好的情況下,它才是提供情緒價值的安慰劑。 尊重技術,善待工程師 阿里云這兩年走了很多人:學人家馬斯克推特大裁員降本增效,人家裁幾千個;你幾萬幾萬的裁;隊伍動蕩,人心不穩,穩定性自然會受到影響。推特一天掛幾次,用戶捏著鼻子罵兩句繼續湊合用,ToB 業務跟著連環裁員連環掛,你看企業用戶可忍得了這個? 很難說這跟企業文化沒有關系:996 修福報,大把時間內耗在無窮的會議匯報上。領導不懂技術,負責匯總周報寫PPT吹牛逼,P9 出嘴;P8 帶隊,真正干活的可能都是些新鮮從業務線薅來的 P6和P7 ;頂尖技術人才與真正能打的人才根本不吃這一套PUA 窩囊氣,成批出來創業單干 —— 環境鹽堿地化:學歷門檻越來越高,人才密度卻越來越低。 我親自見證的例子是,一個獨立開源貢獻者單人搞的 開源 RDS for PostgreSQL,可以騎臉輸出幾十人 RDS 團隊的產品,而對方團隊甚至連發聲辯白反駁的勇氣都沒有 —— 阿里云確實不缺足夠優秀的產品經理和工程師,但請問這種事情為什么可能會發生呢?這是應該反思的問題。 阿里云作為本土公有云中的領導者,應當是一面旗幟 —— 所以它可以做的更好,而不應該是現在這幅樣子。作為曾經的阿里人,我希望阿里云能吸取這次故障的教訓,尊重技術,踏實做事,善待工程師。更不要沉迷于殺豬盤快錢而忘記了自己的初心愿景 —— 為用戶提供物美價廉的公共計算資源,讓計算和存儲資源像水電一樣普及。 References
來源微信公眾號:馮若航 非法加馮 該文章在 2024/3/13 11:32:38 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886