【W(wǎng)EB開(kāi)發(fā)】不要迷信響應(yīng)式編程,它只是編程范式中的“小丑”
當(dāng)前位置:點(diǎn)晴教程→知識(shí)管理交流
→『 技術(shù)文檔交流 』
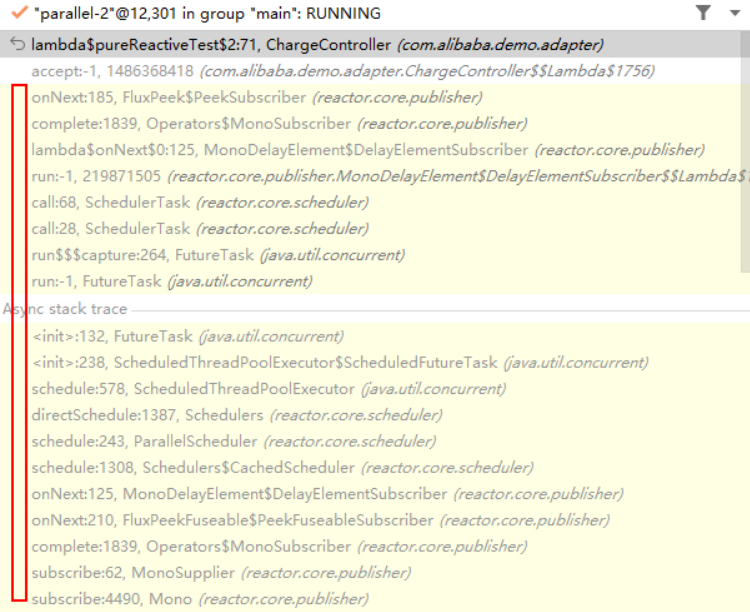
我不是很理解,為什么越來(lái)越多的項(xiàng)目打著高性能的旗號(hào),迷信般的使用響應(yīng)式編程框架,然后把代碼搞的亂七八糟。響應(yīng)式編程真的那么香么?還是“天下苦響應(yīng)式編程久已”,在迫害我們的祖國(guó)花朵?在我看來(lái),響應(yīng)式編程至少犯了三宗罪:1. 易造成復(fù)雜;2. 調(diào)試?yán)щy;3. 性能迷霧。 鑒于此,我希望開(kāi)發(fā)同學(xué)們?cè)谶x擇編程范式的時(shí)候,能擦亮自己的眼睛,選一個(gè)真正適合自己和團(tuán)隊(duì)的編程范式。 罪一、易造成復(fù)雜響應(yīng)式編程的代碼通常比傳統(tǒng)的命令式編程更復(fù)雜。它本質(zhì)上是回調(diào)的封裝,需要將一步一步的操作轉(zhuǎn)換為一個(gè)一個(gè)的回調(diào)。因?yàn)榈讓硬捎玫氖怯^察者模式,需要我們把所有的業(yè)務(wù)操作都注冊(cè)到Publisher里面,然后通過(guò)通知的模式去接收數(shù)據(jù)流動(dòng)。為了發(fā)揮異步的效用,這根鏈條不能斷,這就導(dǎo)致開(kāi)發(fā)人員很容易寫(xiě)出有很多的點(diǎn)、點(diǎn)、點(diǎn)、點(diǎn)….可讀性差、易出錯(cuò)的代碼。如下所示,這是一段真實(shí)的項(xiàng)目代碼示例: 說(shuō)實(shí)話,這還不算糟糕的,比這個(gè)更長(zhǎng)、更爛的Reactive代碼比比皆是。可以說(shuō),但凡采用Reactive編程的項(xiàng)目,基本就是這樣的調(diào)調(diào)。WTF!究其背后原因,我想這可能是因?yàn)轫憫?yīng)式編程鼓勵(lì)函數(shù)式編程,導(dǎo)致很多應(yīng)該被對(duì)象封裝的邏輯得不到封裝和業(yè)務(wù)顯性化的表達(dá)。從而導(dǎo)致長(zhǎng)面條代碼,可讀性可理解性差。另外,因?yàn)槭擎準(zhǔn)秸{(diào)用,多級(jí)回調(diào)之間的變量共享和傳遞也是隱式的,不直觀。對(duì)于多個(gè)變量的傳遞只能用tuple之類的完全沒(méi)有業(yè)務(wù)語(yǔ)義的對(duì)象。這樣的代碼從頭貫穿到尾,一環(huán)套一環(huán),就像一口氣要唱完一首歌,給人透不過(guò)來(lái)氣的感覺(jué)!再加上Reactive自身有非常多的操作符,其認(rèn)知成本高和學(xué)習(xí)曲線長(zhǎng),導(dǎo)致很多同學(xué)很難精通,能把邏輯跑通就謝天謝地了,什么clean code、可讀性、面向?qū)ο笤O(shè)計(jì)統(tǒng)統(tǒng)要給“這玩意”讓路。 就我個(gè)人而言,所有導(dǎo)致代碼可讀性、可理解性、可維護(hù)性下降的行為都是大罪! 我最不能容忍的也正是響應(yīng)式編程的這一罪狀。有一說(shuō)一,我并不排斥函數(shù)式,只是要分場(chǎng)景,比如大數(shù)據(jù)場(chǎng)景下的流式數(shù)據(jù)處理就非常合適用Reactive風(fēng)格的函數(shù)式編程范式。我反對(duì)的是不分青紅皂白的認(rèn)為這個(gè)技術(shù)NB(NB是因?yàn)槲覍?xiě)的代碼別人看不懂?),濫用響應(yīng)式編程污染我們的代碼庫(kù)。對(duì)于大部分的業(yè)務(wù)代碼而言,用簡(jiǎn)單直觀的方式,顯性化的表達(dá)業(yè)務(wù)語(yǔ)義,讓他人能看懂易理解,才是程序員最大的“善”。 罪二、調(diào)試?yán)щy在響應(yīng)式編程中,回調(diào)的堆棧里無(wú)法看到是誰(shuí)放置了這個(gè)回調(diào)。這導(dǎo)致在排查問(wèn)題時(shí)變得非常麻煩,因?yàn)闊o(wú)法準(zhǔn)確追蹤回調(diào)的調(diào)用關(guān)系。傳統(tǒng)的堆棧,不管是調(diào)試時(shí)打的斷點(diǎn),還是日志中的異常棧,都是能看到哪個(gè)函數(shù)出錯(cuò)了,并向上逐級(jí)回溯調(diào)用方。但是響應(yīng)式編程,在這個(gè)callback的堆棧里面是看不到誰(shuí)放置了這個(gè)callback。 如果我在“after delay”上面打上斷點(diǎn),你將看到下面所示的stack,我根本看不到我的前序步驟是什么,只能看到一大堆“無(wú)意義”的框架調(diào)用鏈。這種調(diào)用上下文的丟失對(duì)我們troubleshooting造成了極大的困難。
同樣,對(duì)于上面代碼中拋出的Exception,其異常堆棧是這樣的,完全看不到我從哪里來(lái),WTF! 這種丟失調(diào)用方上下文的行為,是響應(yīng)式編程的第二宗罪! 罪三、性能迷霧使用響應(yīng)式編程同學(xué)的最大理由就是性能提升。關(guān)于這一點(diǎn),我自己親自做了性能測(cè)試,事實(shí)證明想用好Reactive達(dá)到性能提升的目的,也并非易事,需要我們對(duì)其底層線程模型有非常深刻的理解,否則性能不僅不會(huì)提升還可能惡化。測(cè)試的硬件環(huán)境不重要,因?yàn)橹饕菍?duì)比。軟件是這樣的,Web服務(wù)器是Tomcat 9.0.82。壓測(cè)工具是用JMeter發(fā)起1000個(gè)并發(fā),每隔1秒發(fā)送一次,總共發(fā)送5次。我總共測(cè)試了4種情況: 1)情況一,使用普通的Spring MVC實(shí)驗(yàn)代碼如下: 我們用線程sleep 2秒來(lái)模擬業(yè)務(wù)處理時(shí)間,其測(cè)試結(jié)果如下。因?yàn)門(mén)omcat的默認(rèn)最大線程數(shù)是200,當(dāng)壓測(cè)開(kāi)始時(shí),200個(gè)線程會(huì)被全部啟動(dòng)。因?yàn)镾pringMVC是thread-per-request模式,所以其處理的極限也就是100/S(因?yàn)闃I(yè)務(wù)處理需要2s,只有200個(gè)線程,所以每秒能處理的最大并發(fā)是200/2,也就是100),實(shí)測(cè)的結(jié)果是97/sec,可以理解。平均響應(yīng)時(shí)間是10S怎么理解呢?這是因?yàn)榉?wù)器雖然同時(shí)收到了1000個(gè)request,但只有100/sec的處理能力,剩下的都得在緩存里排隊(duì),那么最后排到的那一波,可不就要10s才能返回么。如果并發(fā)量再大,超過(guò)Tomcat默認(rèn)最多接收10000個(gè)connection的上線,緩存里放不下了,request就會(huì)直接被丟掉,或者等待時(shí)間過(guò)長(zhǎng),導(dǎo)致response time太長(zhǎng),發(fā)生TimeOut錯(cuò)誤。
這里我們?nèi)绻鲂阅軆?yōu)化的話,最簡(jiǎn)單的方式就是加大線程數(shù),比如我們可以在application.yml中調(diào)整最大線程數(shù)到400 按照我們上面的計(jì)算邏輯,同樣是sleep 2秒,400個(gè)線程的極限值應(yīng)該是200,實(shí)測(cè)結(jié)果是178/sec,也差不多
2)情況二,使用Spring WebFlux的reactive接下來(lái),我們把普通的MVC,改成WebFlux,看看情況怎么樣,測(cè)試代碼如下: 我們把2s拆成3個(gè)step,分別讓線程sleep 600ms、600ms和800ms,加起來(lái)也是2S。你們覺(jué)得吞吐率會(huì)怎樣?實(shí)測(cè)結(jié)果如下:
同樣是400個(gè)線程的配置,和SpringMVC的并發(fā)量基本是一樣的。這是因?yàn)槲覀兪侵苯釉趀xec線程上使用了sleep,而Mono的操作又是同步順序操作的,所以其效果是和SpringMVC一樣的。這就是我說(shuō)的,如果你不了解WebFlux的底層線程模型,用了Reactive也不一定就能提升性能,甚至還可能導(dǎo)致性能惡化,后面會(huì)提到。 3)情況三,正確的使用異步處理能力上面之所以性能沒(méi)有提升,是因?yàn)槲覀兊膕leep操作block了exec線程,導(dǎo)致異步能力不能發(fā)揮,正確的delay方式應(yīng)該是這樣: 為什么說(shuō)這才是正確的方式呢?我們先來(lái)看一下壓測(cè)的結(jié)果,可以看到通過(guò)這種方式,我們的QPS達(dá)到了452/sec,平均Response Time是2S,性能翻倍了,這個(gè)收益還是很可觀的。但是,前提是我們要用對(duì)。
之所以能達(dá)到這樣的效果,是因?yàn)橥ㄟ^(guò)delayElement我們把延遲操作異步化,Reactor的delay實(shí)現(xiàn)是有專門(mén)的parallel線程來(lái)負(fù)責(zé),然后等到delay時(shí)間到了以后,再通過(guò)事件機(jī)制callback,這樣就不會(huì)阻塞exec線程的執(zhí)行,相當(dāng)于有400個(gè)exec線程一直在接客。關(guān)于這一點(diǎn),我們可以通過(guò)如下的日志得到證實(shí): 4)情況四,手動(dòng)并行化最后,我們來(lái)看一個(gè)可怕的情況。響應(yīng)式編程本身是concurrency-agnostic的,其并發(fā)模型是開(kāi)發(fā)人員自己控制的。因此我們可以手動(dòng)設(shè)置parallel模式,以期達(dá)到并行處理的目的,我們不妨用一個(gè)Flux來(lái)試一試,其代碼如下 上面代碼的意圖是說(shuō)通過(guò)增加parallel線程,讓execute函數(shù)可以并行被執(zhí)行,當(dāng)我們用Postman發(fā)送一個(gè)請(qǐng)求的時(shí)候,很好,因?yàn)椴⑿校緛?lái)需要2s的操作,800ms就返回了,這正是我們想要的。然而,當(dāng)我們啟動(dòng)和前面實(shí)驗(yàn)一樣的1000個(gè)并發(fā)壓測(cè)時(shí),慘不忍睹的事情發(fā)生了:
吞吐量降低到只有37/sec,延遲達(dá)到了26s,因?yàn)槌瑫r(shí)造成96%的錯(cuò)誤率。 這就是我說(shuō)的,用不好可能導(dǎo)致性能惡化的情況。造成這種情況的原因是,系統(tǒng)的默認(rèn)的parallel線程數(shù)等于cpu的核數(shù),我電腦是8核的,所以這里有8個(gè)parallel線程,又因?yàn)槲覀兪謩?dòng)block了parallel線程,導(dǎo)致瓶頸點(diǎn)積壓到8個(gè)parallel線程身上。盡管在外圍我們有NIO的無(wú)阻塞acceptor接收請(qǐng)求,分發(fā)給400個(gè)exec線程工作,但都被block在8個(gè)parallel線程這里了,相當(dāng)于整個(gè)系統(tǒng)只有8個(gè)線程在工作,不慢才怪。 所以通過(guò)測(cè)試,我發(fā)現(xiàn)以Spring WebFlux為代表的響應(yīng)式編程在性能這一塊就像是一團(tuán)迷霧,這是它的第三宗罪!如果不能深入理解其背后的工作機(jī)理和線程模型,不僅難以提升性能,還可能把事情搞砸。與其這樣,還不如不用,通過(guò)簡(jiǎn)單的增加exec線程數(shù)量來(lái)提升并發(fā)處理能力不香么! 從BIO,Non-blocking IO到Async IO,我們切實(shí)感受到了底層技術(shù)進(jìn)步帶來(lái)的性能提升,而且這樣的提升是對(duì)上層業(yè)務(wù)代碼透明的,這點(diǎn)很好。然而,響應(yīng)式編程并不是性能提升的直接原因,它只是一種編程范式。因此,請(qǐng)不要把響應(yīng)式編程和高性能畫(huà)等號(hào)。通過(guò)上面的實(shí)驗(yàn),你也看到了,想用好Reactive去提升性能也并非易事。 再說(shuō)了,在這個(gè)硬件廉價(jià),數(shù)據(jù)中心CPU平均使用率不到10%的世界里,業(yè)務(wù)應(yīng)用的性能真不是什么大不了的事。如果要在可維護(hù)性和性能之間tradeoff的話,傾向前者絕對(duì)是明智的,那點(diǎn)性能提升,相比較于代碼惡化,造成的高昂軟件人力維護(hù)成本來(lái)說(shuō),根本不值得一提!。所以不要再迷信、吹捧響應(yīng)式編程了,它既不是什么先進(jìn)技術(shù),也不是什么高級(jí)的編程范式,它只是一個(gè)有罪在身的“小丑”。忍不了它的三宗罪,就大膽放棄不要用,NO BIG DEAL! 該文章在 2024/5/23 18:27:31 編輯過(guò) |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開(kāi)發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")