Windows藍屏致損150億美元,受災者僅獲賠10美元引熱議,程序員激辯用Rust能否改寫史上最大IT故障結局?
當前位置:點晴教程→知識管理交流
→『 企業管理交流 』
編譯 | 鄭麗媛 出品 | CSDN(ID:CSDNnews) 距離 Windows 大范圍藍屏事件,已經過去了 6 天。 這 6 天來,國內外技術網站仍對此事熱議不斷,“罪魁禍首” CrowdStrike 的名字被頻繁提及,與之伴隨的無一不是質疑和譴責:
基于此,本周 CrowdStrike 的股價已迅速暴跌超 20%。出于對引發此次故障的歉意,據悉昨日 CrowdStrike 還向其合作方均提供了一張價值 10 美元的 Uber Eats 禮品卡作為道歉:“為了表達我們的歉意,你的下一杯咖啡或夜宵由我們請客!”不過,有收到該禮品卡的用戶表示,他們去兌換時,頁面提示稱該禮品卡“已被發行方取消,不再有效”。 除了以上聚焦于 CrowdStrike 本身的關注和報道,近日還有一個話題也在開發者圈內引起了不小的討論:”如果 CrowdStrike 改用 Rust 的話,全球 850 萬 PC 是不是就不會藍屏了?“
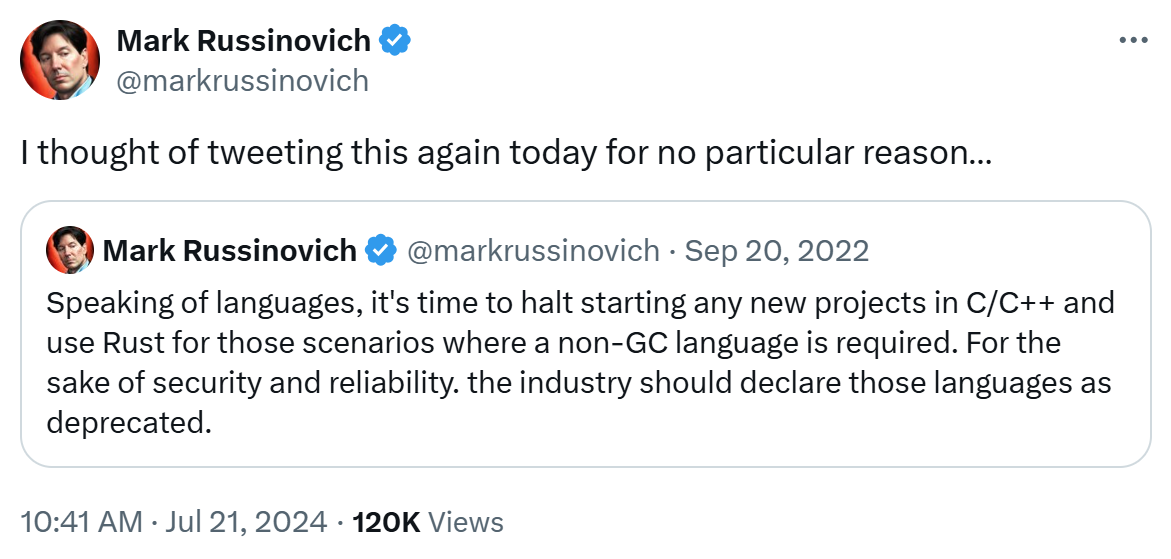
不僅如此,微軟 Azure 部門 CTO Mark Russinovich 也在事發后轉了一條他 發布于 2022 年的推文:“說到語言,現在是時候停止用 C/C++ 啟動任何新項目了,請在需要使用非 GC 語言的情況下使用 Rust。為了安全性和可靠性,業界應該宣布這些語言已被淘汰。”
眼看著不少 Rust 狂熱愛好者開始放話“沒錯,Rust 就是唯一答案”,一位同樣喜歡 Rust 的資深軟件工程師 Julio Merino,在理智地進行了一番全盤分析后得出結論:“就算是 Rust,也救不了這次 CrowdStrike 的中斷事故。”
以下為譯文: 我非常喜歡 Rust,也很贊同不應繼續使用 C++ 這類內存不安全的編程語言,但我還是要說:那些聲稱用 Rust 就可以避免上周五全球大面積網絡中斷的說法太夸張了,對 Rust 的口碑有害無益。 如果 CrowdStrike 是用 Rust 編寫的,那確實可以降低發生故障的可能性,但它并不能解決導致故障發生的根本原因。所以看到許多人說 Rust 是解決這次事故的唯一答案,我就感到非常惱火——這種說法,不僅無法推動 Rust 的普及,反而會招來反感:C++ 專家們都知道本次事故的根本原因,看到這種誤導性說法必然不快,從而導致系統編程世界的進一步分裂。 那么,為什么說 Rust 不能解決這個問題呢?接下來我會試著回答這個問題,同時也深入探討一下造成這次故障的原因。
故障分析 以下是來自 CrowdStrike 官方的“事后分析”:
把上面這段話翻譯為“人話”,就是: 1、CrowdStrike 公司推送了一項配置更新。 2、該更新觸發了“Falcon 平臺”中的一個潛在 bug。 3、Falcon 中的這個 bug 導致了 Windows 崩潰。 前兩點并不奇怪:對于任何在線系統來說,變更配置都是“家常便飯”,而這些更新引發代碼中的 bug 也是常見現象。事實上,大多數宕機事件都是由人為配置變更造成的。 顯然,我們應該問問為什么這個 bug 會存在,以及如何修復它以提高產品的穩定性。但我們別忘了第三點:為什么這個 bug 能夠導致整臺機器癱瘓?更重要的是,為什么這個 bug 會讓全球如此多的系統宕機?
內存錯誤 讓我們從第一個問題開始:Falcon 中的 bug 是什么性質的? 很簡單:在“Channel Files”(又稱配置文件)解析器中存在一個邏輯錯誤,當遇到一些無效輸入時,這段代碼會試圖訪問一個無效的內存位置。具體細節并不重要:可能是取消引用空指針,也可能是一般保護故障等等。關鍵在于:崩潰是由無效內存訪問問題引發的。 這時,一些 Rust 狂熱粉可能會跳出來說::“看啊,果然!如果代碼是用 Rust 寫的,這個 bug 就不會存在!”我無法否認這個說法:如果用 Rust,這個特定的 bug 確實不會出現。 但那又怎樣?就算避免了這種類型的 bug,下一次遇到 Rust 也無法避免的 bug 時,該宕機還是會宕機——無視 Falcon 的本質問題、只關注內存錯誤的行為,好比“只見樹木,不見森林”。 那么,Falcon 究竟是什么呢?
內核崩潰 在我看來,Falcon 是一種“惡意軟件......不過是好人的惡意軟件”,也就是一個終端安全系統。Falcon 通常安裝在企業機器上,以便安全團隊能夠實時檢測并解除威脅(同時監控員工的行為)。這確實有一定價值:大多數網絡攻擊都是通過社會工程學手段從入侵企業機器開始的。 這種類型的產品必須對機器有控制權,它必須能夠攔截所有用戶的文件和網絡操作以掃描其內容,并且還必須是防篡改的,以防“精明”的企業用戶在閱讀到一些網上修復 WiFi 的可疑指導后嘗試禁用它,以避免提交 IT 工單。 如何實現像 Falcon 這樣的產品?最簡單的方法,也是 Windows 鼓勵的方法,就是編寫一個內核模塊。很明顯,Falcon 是一個內核模塊,因此它運行在內核空間。這就意味著,Falcon 代碼中的任何錯誤都可能破壞正在運行的內核,進而導致整個系統崩潰。 我所說的“任何錯誤”,是真的。內核不僅會因為內存錯誤而崩潰,也不一定非要“內核崩潰”才能讓機器無法使用:死鎖會讓阻止內核前進,系統調用處理程序中的邏輯錯誤會阻止用戶空間之后打開任何文件,一個無限遞歸算法會耗盡內核的堆棧……破壞內核穩定性的方法實在是太多了,所以我說就算是 Rust 也不能完全避免這種事故的發生。 Rust 的內存安全性只能解決一種類型的崩潰。另外,Rust 生態系統中對正確性的關注也確實可以最大限度地減少其他類型邏輯錯誤的出現。但是……雖然我們都希望做到完美,但也必須接受錯誤會發生的事實——斷言 Rust 是解決問題的唯一答案和堅持使用 C++ 一樣,都是不負責任的行為。 要知道,在內核空間工作的 C++ 開發者,要比了解內核內部結構的 Rust 開發者多得多。因此,大部分 C++ 開發者都知道這種說法的可笑之處,同時也會增加兩個社區之間的敵意,更是完全違背了讓人們轉向安全語言的這個目標。Rust 開發者知道 Rust 確實可以改善現狀,但 C++ 開發者無法接受,因為他們聽到的觀點無法引起他們的共鳴。
從內核空間到用戶空間 還有人說,如果 Falcon 不在內核中運行,就根本不會發生這種情況。嗯,這個說法要好一點,但……僅此一點也不一定就能解決問題。 正如我之前提到的,Falcon 需要盡可能防篡改,防止惡意軟件對其進行干擾,并防止被入侵的用戶試圖禁用它。如果惡意軟件或人類能夠輕易做到這一點,那么這個產品就毫無用處。 現在,Windows 內核完全有能力禁止類似 Falcon 的內核模塊。相反,內核可以暴露一系列 API,讓用戶空間的應用程序能夠接入這些 API 來提供類似的功能。你知道嗎,微軟確實嘗試過讓 Windows 朝這個方向發展,但殺毒軟件公司威脅要以反壟斷為由起訴,結果整個計劃無疾而終。因此,我們現在只能忍受一個安全性較低的系統,因為殺毒軟件公司需要銷售那些煩人的產品。 但是,我們先暫時放下這個麻煩不談。即使 Falcon 運行在用戶空間,并通過受控 API 與內核通信……這就足以防止系統故障嗎?請注意,這些 API 也需要防篡改。試想一下,如果你希望這個用戶空間驅動程序在內核執行每個二進制文件之前進行驗證,也就是讓內核在每次執行時都需要從用戶空間驅動程序獲得答案,而這個驅動程序又有問題,那么系統將無法再執行任何程序。 可如果你讓內核與驅動程序通信變成可選項,以便內核可以容忍崩潰的驅動程序,那么就等于給惡意軟件開了一條路,它們可以先嘗試崩潰驅動程序,然后再入侵系統。 因此,僅僅“遷移到用戶空間”顯然也不是解決辦法。
部署中的漏洞 如果我們必須接受 bug 的存在,而內存相關的 bug 并不是唯一會導致系統崩潰的原因,且將驅動程序移到用戶空間也不是很好的解決方案……那難道就無計可施了?真的沒有辦法防止這種情況發生嗎? 以上我說的這些,都是可以(也應該)采取的措施,以減少系統故障發生的概率,但我們必須接受這樣一個事實:這次代碼 bug 只是特定的觸發因素,就算換一個觸發因素也可能會產生類似的惡果。本次全球宕機事件的根本原因,在于配置變更的發布流程。 根據 SRE 101(或 DevOps,隨便你怎么叫)規定,配置變更必須分階段進行,以緩慢和受控的方式部署,并在每個步驟進行驗證。這些變更應該先在很小的范圍內進行驗證,然后再向全球推送,而且每次推送都應是漸進的。 考慮到 Falcon 的關鍵性以及 bug 可能帶來的巨大影響,我很難相信 CrowdStrike 沒有對部署進行任何驗證。但根據 CrowdStrike 最新更新的事后分析來看,他們確實沒有進行任何形式的測試或金絲雀部署(在將更改推廣到整個服務集群之前,先把更改推廣到一小部分用戶進行測試),這實在是令人難以置信的疏忽。 所以說,CrowdStrike 的部署實踐是造成此次事件的罪魁禍首——也就是說,這次宕機事件是一個流程問題,而不是代碼或技術問題,改用 Rust 也無濟于事。
CrowdStrike 發布初步審查報告,總結:“測試和流程不完善” 誠然如 Julio Merino 所說,CrowdStrike 在其官網最新發布了此事件的初步審查報告,并公開了此次事件的整體時間線:
部分網友在看過 CrowdStrike 這份冗長的初步審查報告后,精辟總結:“說了這么多,就是想說我們的測試和流程不完善,不小心把垃圾發布出來了”;“字數驚人,但歸根結底還是測試代碼有 bug 以及測試不夠”;“不好意思,我們對此更新進行的唯一測試,是一個沒真正通過的自動化測試”。 因此對于這種事故原因,絕對不是改用 Rust 就能解決的,根本還是在于測試環節和部署流程的不規范。與此同時,CrowdStrike 也在事后總結中表示,今后要在發布更新前增加軟件測試,并逐步推出更新,具體補救措施大體分為三個部分: 1、軟件彈性和測試 (1)通過使用以下測試類型改進快速響應內容測試:本地開發人員測試,內容更新和回滾測試,壓力測試、模糊測試和故障注入,穩定性測試和內容接口測試; (2)在快速反應內容的驗證器中增加額外的驗證檢查; (3)增強內容解釋器中現有的錯誤處理功能。 2、快速響應內容部署 (1)對快速響應內容實施交錯部署策略,從金絲雀部署開始,再逐步將更新部署到更大的區域; (2)改進對傳感器和系統性能的監控,在快速響應內容部署期間收集反饋信息,以指導分階段部署; (3)允許用戶選擇部署的時間和位置,使其能夠更好地控制快速響應內容更新的交付; (4)通過客戶可訂閱的發布說明提供內容更新詳情。 3、第三方驗證 (1)進行多個獨立的第三方安全代碼審查; (2)對從開發到部署的端到端質量流程進行獨立審查。 參考鏈接: https://www.crowdstrike.com/falcon-content-update-remediation-and-guidance-hub/ https://blogsystem5.substack.com/p/crowdstrike-and-rust 該文章在 2024/7/26 16:40:04 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886