在數據庫查詢中��,模糊查詢是一個非常常見的需求�,特別是在處理大量數據時。許多開發者在使用Oracle數據庫時�,經常習慣性地使用 LIKE 's%' 來實現模糊查詢��,以獲取以特定字母開頭的數據���。你想過 LIKE 被大多數場景使用,這可能會有什么問題嗎�? 首先���,雖然 LIKE 的確能滿足基本的模糊匹配需求�����,但它并不是萬能的。在某些情況下��,過度依賴 LIKE 可能會導致性能問題�。比如,當表中數據量非常龐大時���,使用 LIKE 進行模糊查詢可能會導致全表掃描,這樣不僅耗時����,還會增加數據庫的負擔�。 其次�,LIKE 的使用邏輯并不總是清晰。很多時候�����,我們可能想要的不僅僅是以某個字符開頭的數據����,而是包含特定字符或者符合其他更復雜的條件。這時候���,單純的 LIKE 's%' 就顯得有些力不從心了。比如�,如果你想找到所有包含字母“s”的記錄���,使用 LIKE 就無法實現了�,而這時使用正則表達式(REGEXP)會更加靈活和高效���。 再者����,使用 LIKE 可能會讓查詢的意圖不夠明確�����。我們在編寫 SQL 查詢時����,應該盡量讓查詢邏輯清晰易懂���。如果只是一味地使用 LIKE��,可能會導致代碼可讀性降低�,其他開發者在維護時就會感到困惑���。 那么��,如何才能在模糊查詢中更好地表達我們的意圖呢����?首先�����,建議結合其他條件進行查詢�����。例如,如果我們想要找到所有以“s”開頭并且年齡大于30歲的員工,可以這樣寫:SELECT * FROM employeesWHERE name LIKE 's%' AND age>30;
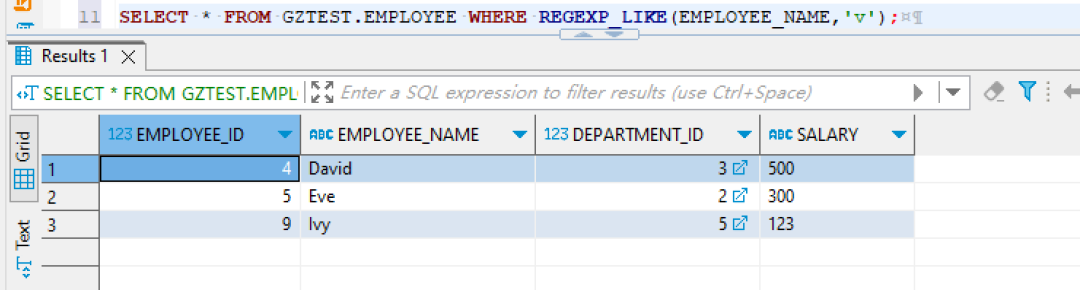
這樣的查詢不僅能夠提高查詢的精確度,還能提升性能��。 另外�����,考慮使用正則表達式也是一個不錯的選擇�����。Oracle支持的 REGEXP_LIKE 函數可以讓我們進行更復雜的模式匹配。例如,查找所有包含字母“s”的名字,可以這樣寫:SELECT * FROM employees WHERE REGEXP_LIKE(name,'s');
模糊查詢是數據庫操作中不可或缺的一部分����,但Like絕對不是唯一的方式����,我們不能僅僅依賴于 LIKE���。在實際開發中���,合理選擇查詢方式����,清晰表達查詢意圖,才能真正提升數據庫查詢的效率和效果�。 REGEXP_LIKE 函數在處理復雜或靈活的字符串匹配時����,相對于簡單的 LIKE 操作符�����,提供了更加強大和靈活的方式。它不僅提升了代碼的可讀性和維護性�,還能有效滿足復雜查詢的需求��。在實際開發中,合理選擇使用 LIKE 和 REGEXP_LIKE 可以幫助開發者編寫出更高效��、更清晰的代碼����。簡單的來說,簡潔用like�,復雜的業務用 REGEXP_LIKE�����,因為它更加靈活。
該文章在 2024/12/12 10:32:15 編輯過






 400 186 1886
400 186 1886