在咱們日常的工作和學習里,總會遇到各種各樣的 PDF 文件,像合同、資料、文件之類的,數都數不過來。雖說 PDF 文件挺常用的,可一旦涉及到從里頭提取文字,那可就讓人頭疼了。很多時候,復制出來的文字不是格式亂了,就是出現一堆亂碼,根本沒法直接用,得花不少時間去調整和整理。

但是!今天要給大家介紹一個超厲害的開源工具 ——OCRmyPDF,有了它,你就能輕松搞定 PDF 文件里的文字提取問題,絕對是讓你對 PDF 文件刮目相看的神器!
軟件介紹
OCRmyPDF 是一個開源的 Python 腳本工具,旨在通過OCR(光學字符識別)技術,將掃描的PDF文件中的圖像內容轉化為可搜索、可復制粘貼的文本層。簡單來說,它能將PDF文件中的文字提取出來,同時保留原有的圖像分辨率,確保用戶能夠輕松復制和粘貼內容。這個工具不僅支持多種語言,還能夠處理數千頁的文件,堪稱PDF處理領域的神器!
主要功能
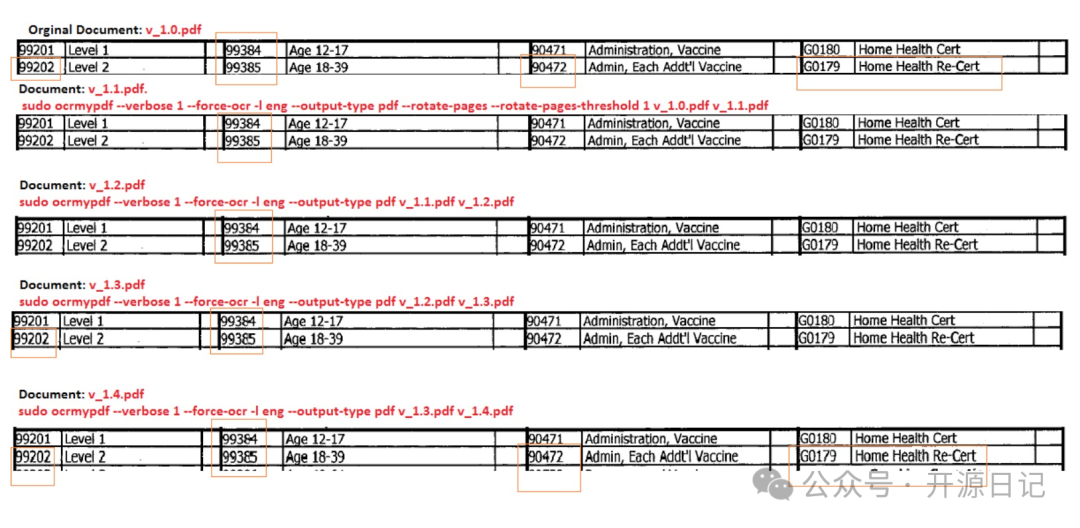
- OCR文本提取與保留圖像分辨率OCRmyPDF 的核心功能是將PDF文件中的OCR文本提取出來,并將其準確地放置在圖像下方,這樣用戶就可以輕松復制和粘貼文字內容。同時,它能夠保留原始圖像的分辨率,避免因壓縮或調整而丟失質量。
- 多語言支持作為Tesseract OCR引擎的親兒子,OCRmyPDF 支持超過100種語言,無論是中文、英文還是其他語言,都能輕松識別并提取。
- 優化PDF圖像通過OCRmyPDF,用戶可以優化PDF圖像,通常生成的文件比輸入文件小,節省存儲空間。
- 預處理功能OCRmyPDF 提供了預處理功能,用戶可以根據需求對圖像進行校正或清理,然后再進行OCR識別,確保后續操作的準確性。
- 無損插入OCR信息該工具能夠盡可能以無損方式插入OCR信息,不會干擾其他內容,確保文件的完整性和可編輯性。
- 多核支持OCRmyPDF 在所有可用的CPU核心上分配工作,能夠高效處理大量文件,提升處理速度。
開源成就
目前已經獲得16.5K Star
安裝指南
安裝OCRmyPDF非常簡單,它支持多種操作系統:
- Linux:通過包管理器安裝,例如
apt install ocrmypdf。 - macOS:通過 Homebrew 或其他工具安裝。
- FreeBSD:通過
pkg install py-ocrmypdf 安裝。
安裝完成后,用戶可以通過命令行運行工具,根據需求添加OCR層、轉換文件格式或處理其他操作。
功能展示
生成 PDF/A 文件
ocrmypdf input.pdf output.pdf
說明:添加 OCR 層,生成 PDF/A 格式文件,適合長期保存。
生成普通 PDF 文件
ocrmypdf --output-type pdf input.pdf output.pdf
說明:添加 OCR 層,生成普通 PDF 文件,適合日常使用。
生成 PDF 和文本文件
ocrmypdf --sidecar output.txt input.pdf output.pdf
說明:生成 PDF 文件的同時,提取文字到單獨的文本文件,方便后續處理。
OCRmyPDF 是一個功能強大且易于使用的工具,能夠幫助用戶高效處理PDF文件。無論是提取OCR文本、優化圖像還是處理多語言文件,它都能提供卓越的表現。如果你正在尋找一款能夠提升PDF處理效率的工具,OCRmyPDF絕對值得一試!
開源地址: https://github.com/ocrmypdf/OCRmyPDF/
閱讀原文:原文鏈接
該文章在 2025/2/10 10:14:49 編輯過






 400 186 1886
400 186 1886


