首先什么是io復用呢?
現在web框架沒有不用到io復用的,這點是肯定的,不然并發真的很差。
那么io復用,復用的是什么呢?復用的真的不是io管道啥的,也不是io連接啥的,復用的是io線程。
這其實是操作系統的設計上的io并發不足的地方,然后自己給慢慢填了。
聽一段歷史:
當時操作系統設計的時候呢? 按道理說是要操作系統去管理io這塊,也就是對我們屏蔽硬件。
然后我們就調用系統的接口,讓操作系統去幫我們讀取數據啥的,這似乎是非常的nice的時候。
操作系統就設計了兩種讀取方案:
第一種呢,比如自己調用io系統接口,然后線程陷入等待,當有數據的時候呢,操作系統喚醒我們的線程
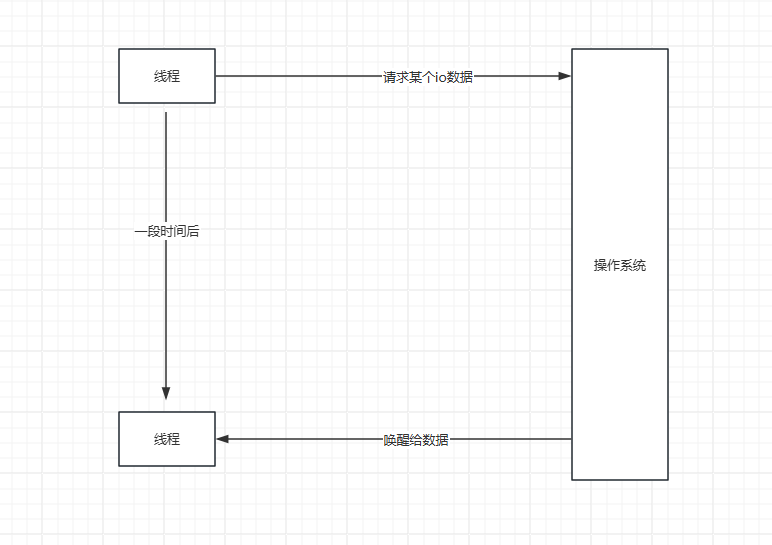
第二種,就是自己調用系統接口,然后操作系統告訴我們沒有,這個時候我們可以選擇做其他事情,或者等會再來問。
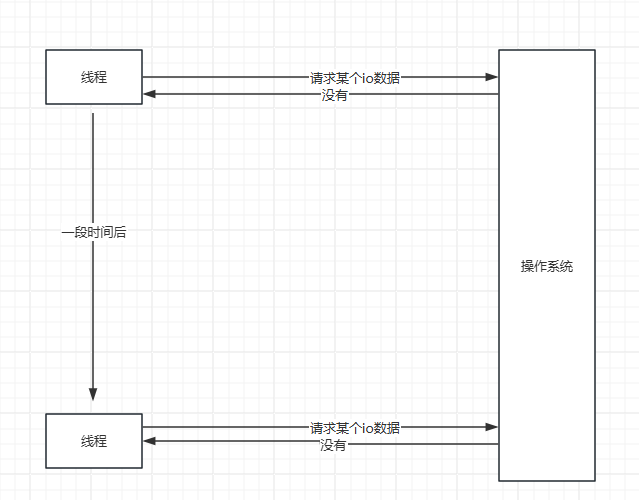
因為對io是抽象的,這個時候呢,如果是磁盤文件系統,這還是相當nice的,因為我們又不關心是網絡io還是文件io,讀取就完事了。
磁盤文件我們一般是對某個文件連續讀對吧,這樣這兩種方式工作都是很好的。
可能有些人一直認為讀磁盤文件就是立即返回的,其實可以調用其他方式,當磁盤有新數據的時候再返回,是可以的,在操作系統系統會補全這些機制的說明,這里不擴展。
但是網絡io有個什么樣的場景呢?那就是連接數可能特別多,而且是每個間斷著讀取。
加入我們采用第一種方式,那么每一個連接,就需要一個線程去監控,這樣就會很多線程,這樣的確會出現線程大爆炸,而且線程調度是需要開銷的。
那么我們采用第二種方式,第二種方式好像每個都需要一個線程,其實不需要哈。
我們可以排隊嘛,比如把socket放入到一個隊列中,然后不斷地輪訓,這樣其實就實現了io復用了,這個時候就有人問了,io復用這么簡單嗎?
是的,這就是io復用了。呀呀呀,這就實現了,是的,這就實現了io線程復用,就是一個或者多個線程實現io的數據接收嘛。
但是性能不太行,不太行的地方在于兩點,就是加入有5000個連接,只有2個有信息,那么得去輪訓一遍,這效率真的很感人。
還要就是不斷地調用操作系統的陷入這個開銷也是很大的。
那么這個時候操作系統自己就得改進了,明明就是操作系統自己知道有沒有消息,為啥不主動告訴我呢?
那么操作系統自己做了一些改進。
select 函數.
#define __FD_SETSIZE 1024
typedef struct {
unsigned long fds_bits[__FD_SETSIZE / (8 * sizeof(long))];
} __kernel_fd_set;
struct timeval {
time_t tv_sec;
suseconds_t tv_usec;
};
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
通過select函數可以完成多個IO事件的監聽。
函數參數:
readfds:內核檢測該集合中的IO是否可讀。如果想讓內核幫忙檢測某個IO是否可讀,需要手動把文件描述符加入該集合。
writefds:內核檢測該集合中的IO是否可寫。同readfds,需要手動加入
exceptfds:內核檢測該集合中的IO是否異常。同readfds,需要手動加入
nfds:以上三個集合中最大的文件描述符數值 + 1,例如集合是{0,1,4},那么 maxfd 就是 5
timeout:用戶線程調用select的超時時長。
設置成NULL,表示如果沒有 I/O 事件發生,則 select 一直等待下去。
設置為非0的值,這個表示等待固定的一段時間后從 select 阻塞調用中返回。
設置成 0,表示根本不等待,檢測完畢立即返回。
函數返回值:
大于0:成功,返回集合中已就緒的IO總個數
等于-1:調用失敗
等于0:沒有就緒的IO
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);
select 缺點:
1.fd_set長度限制:由于fd_set本質是一個數組,同時操作系統限制了其長度,導致其只能接受文件描述符數值在1024以內的。
2. select函數的返回值是int,導致每次返回后,用戶得手動檢測集合中哪些值被改為1了(被改為1的表示產生了IO就緒事件)
3. 每次調用 select,都需要把 fd 集合從用戶態拷貝到內核態,當fd很多時,開銷很大。
4. 每次內核都是線性掃描整個 fd_set,判斷是否有IO就緒事件,導致隨著監控的描述符 fd 數量增長,其性能會線性下降
看到select缺點這么多,看著就不怎么好用。
這個其實就是批量檢測,然后加了一個timeout,最后還得自己去輪訓一遍,還是有點坑。
這時候可能我們都會想,自己設計都不會這么坑。其實這樣設計也是當時的一個常規設計,因為既要保全內核的穩定,又要維護陷入函數的簡單,后面就能看到數據結構之美了。
然后就到了poll了:
和 select 相比,它使用了不同的方式存儲文件描述符,也解決文件描述符的個數限制。
struct pollfd {
int fd;
short events;
short revents;
};
int poll(struct pollfd *fds, unsigned long nfds, int timeout);
函數參數:
fds:struct pollfd類型的數組, 存儲了待檢測的文件描述符,struct pollfd有三個成員:
fd:委托內核檢測的文件描述符
events:委托內核檢測的fd事件(輸入、輸出、錯誤),每一個事件有多個取值
revents:這是一個傳出參數,數據由內核寫入,存儲內核檢測之后的結果
nfds:描述的是數組 fds 的大小
timeout: 指定poll函數的阻塞時長
-1:一直阻塞,直到檢測的集合中有就緒的IO事件,然后解除阻塞函數返回
0:不阻塞,不管檢測集合中有沒有已就緒的IO事件,函數馬上返回
大于0:表示 poll 調用方等待指定的毫秒數后返回
函數返回值:
-1:失敗
大于0:表示檢測的集合中已就緒的文件描述符的總個數
在 select 里面,文件描述符的個數已經隨著 fd_set 的實現而固定,沒有辦法對此進行配置;而在 poll 函數里,我們可以自由控制 pollfd 結構的數組大小,從而突破select中面臨的文件描述符個數的限制。
這個pollfd就設計的人性化多了哈,有個fd然后里面是事件,看起來還是不錯的,很面向對象。
poll 的實現和 select 非常相似,只是poll 使用 pollfd 結構,而 select 使用fd_set 結構,poll 解決了文件描述符數量限制的問題,但是同樣需要從用戶態拷貝所有的 fd 到內核態,
也需要線性遍歷所有的 fd 集合,所以它和 select 并沒有本質上的區別。
所以呢,有人如果系統用poll和epoll比,這兩個思想就不一樣,下文可見,poll只是在select上進行輕微的改進,和操作系統的溝通真的很感人,但是這個結構化,還是很舒服的,尤其是寫了很多面向對象代碼后
epoll 是 Linux kernel 2.6 之后引入的新 I/O 事件驅動技術,它解決了select、poll在性能上的缺點,是目前IO多路復用的主流解決方案。
epoll 實現:
int epoll_create(int size);
int epoll_create1(int flags);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
struct epoll_event {
__uint32_t events;
epoll_data_t data;
};
union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
};
typedef union epoll_data epoll_data_t;
1.epoll_creare、epoll_create1:這兩個函數的作用是一樣的,都是創建一個epoll實例。
2. epoll_ctl:在創建完 epoll 實例之后,可以通過調用 epoll_ctl 往 epoll 實例增加或刪除需要監控的IO事件。
epoll_ctl:在創建完 epoll 實例之后,可以通過調用 epoll_ctl 往 epoll 實例增加或刪除需要監控的IO事件。
epfd:調用 epoll_create 創建的 epoll 獲得的返回值,可以簡單理解成是 epoll 實例的唯一標識。
op:表示是增加還是刪除一個監控事件,它有三個選項可供選擇:
EPOLL_CTL_ADD: 向 epoll 實例注冊文件描述符對應的事件;
EPOLL_CTL_DEL:向 epoll 實例刪除文件描述符對應的事件;
EPOLL_CTL_MOD: 修改文件描述符對應的事件。
fd:需要注冊的事件的文件描述符。
epoll_event:表示需要注冊的事件類型,并且可以在這個結構體里設置用戶需要的數據。
events:表示需要注冊的事件類型,可選值在下文的 Linux 常見網絡IO事件定義中列出
data:可以存放用戶自定義的數據。
人性化來了,可以自己刪除和添加了,不用一次性給了。
3.epoll_wait:調用者進程調用該函數等待I/O 事件就緒。
epfd: epoll 實例的唯一標識。
epoll_event:相關事件
maxevents:一個大于 0 的整數,表示 epoll_wait 可以返回的最大事件值。
timeout:
-1:一直阻塞,直到檢測的集合中有就緒的IO事件,然后解除阻塞函數返回
0:不阻塞,不管檢測集合中有沒有已就緒的IO事件,函數馬上返回
大于0:表示 epoll 調用方等待指定的毫秒數后返回
在內核中eventpoll結構如下:
struct eventpoll {
wait_queue_head_t wq;
struct list_head rdllist;
struct rb_root_cached rbr;
}
wq:當用戶進程執行了epoll_wait導致了阻塞后,用戶進程就會存儲到這,等待后續數據準備完成后喚醒。
rdllist:當某個文件描述符就緒了后,就會從rbr移動到這。其本質是一個鏈表。
rbr:用戶調用epoll_ctl增加的文件描述都存儲在這,其本質是一顆紅黑樹。
先不介紹紅黑樹,到了紅黑樹介紹的時候再畫圖,不然這個過程可能比較難理解為啥epoll這么高效,除非利用了紅黑樹,那么看下這個改變的地方。
- 我們多個進程可以監控利用epoll_ctl進行監控,其實一般就一個,根據業務也可以多個
- 當觸發事件的時候呢,就觸發的事件再rbr中移除,然后加入到了rdllist中(之所以要移除就說明觸發了,就不需要再繼續監控該事件了唄)
- 當rdllist里面有事件后,那么就會獲取到wq等待的進程,進行通知,也就是說epoll_wait就已經返回了相關的epoll_event,不需要再輪訓一遍了
相當人性化哈,這是我們理解了我們作為用戶和操作系統直接的溝通橋梁塑造好了,所以效率也就高了。
那么問題來了,為啥epoll的效率這么高呢,除了解決和操作系統的溝通問題,還要什么經過優化呢,后續關于紅黑樹的介紹,黑紅樹之所以再這里能發揮作用就是因為其頻繁的加入和刪除,以及遍歷。
那么請問epoll是阻塞io,還是非阻塞io呢?
那肯定是阻塞io嘛,有個timeout當事件到了就返回了,但是也屬于阻塞。
然后呢,我們如果用c語言的時候,發現網絡io和磁盤io其實是用不同的庫,但是他們也的確可以用的底層函數read讀取,都抽象成文件了嘛,之所以用不同的庫是因為這兩個方向針對的場景的確不同,庫嘛,肯定是幫忙封裝好了的,用好庫比啥都重要。
轉自https://www.cnblogs.com/aoximin/p/18347523
該文章在 2025/2/14 11:30:52 編輯過






 400 186 1886
400 186 1886


