一、前言
在當今這個信息爆炸的時代,人工智能技術正以前所未有的速度發展。其中,DeepSeek 作為新一代的 AI 選手,迅速成為行業內的焦點。DeepSeek 在多項性能測試中已經達到了 OpenAI 的最新大模型 o1 水平,部分項目還實現了超越,在多項評測中表現優異,甚至直逼世界頂尖的閉源模型 GPT-4o 和 Claude-3.5-Sonnet。
目前,我們已經在公司的高性能服務器上完成了本地 AI 智能助手部署的 demo,通過大參數量的 DeepSeek 本地大模型(70b 及以上)與豐富的本地知識庫相結合,成功創建了 “虛擬 CST/ABAQUS 技術支持工程師” 這一 AI 智能體,驗證了 AI 模型 + 行業本地知識庫在業務中的實際運用效果。
二、技術方案概述
2.1 整體架構:DeepSeek-R1 模型與 RAG 技術相結合
在選擇 AI 模型時,我們考慮引入 DeepSeek 本地大模型,并結合 RAG(Retrieval-Augmented Generation)技術構建整體架構。

RAG 技術工作思路:先解析本地數據庫,將文本、圖像或其他類型數據轉換成高維向量,而后將原始問題和引用的知識內容以向量形式整合到生成模型的輸入中,增強生成的文本質量
DeepSeek 是一款專注于推理的模型,特別適用于利用已有的知識庫高效回答客戶問題。其高效的推理能力和多模態融合特性,使得 DeepSeek 在處理復雜邏輯任務和長文本時表現出色。DeepSeek-R1 不僅在數學、代碼和自然語言推理等任務上表現卓越,性能直接對標 OpenAI 的 o1 正式版,同時使用 MIT 協議以開源形式向全球開發者開放。
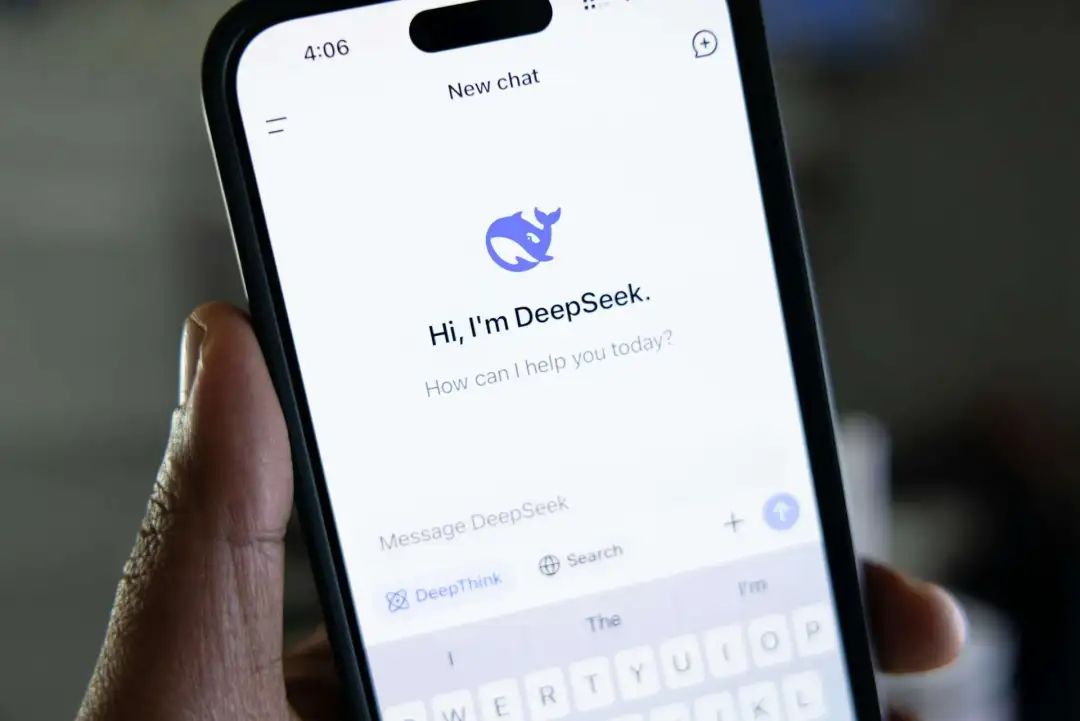
而 RAG 技術則通過檢索增強生成,進一步提升模型的檢索和生成能力。通過從外部知識庫中檢索相關信息,并將這些信息整合到生成模型的輸入中,以增強生成的文本質量、準確性和相關性。
在知識庫中導入文檔后,系統會通過分塊處理將文檔切割為語義連貫的片段(Chunk)。這些文本塊會經過嵌入模型(Embedding Model)轉化為高維向量,存儲至向量數據庫(Vector DB)。當用戶發起問答請求時,系統通過向量相似度檢索匹配的文本片段,并將問題與相關上下文共同輸入大語言模型(LLM),完成檢索增強生成(Retrieval-Augmented Generation,RAG)的智能問答流程。
RAG 技術對本地知識庫處理的流程圖,圖源 Cherry Studio 官方文檔
這種方法能有效解決大型語言模型在處理訓練數據外信息時的 “幻覺” 問題。文獻表明,RAG 技術通過動態檢索外部知識庫實現行業適配(Lewis et al., 2020),這種架構既保留了通用模型的對話能力,又能通過知識庫更新擴展專業認知邊界。現有研究表明其綜合成本顯著低于全參數微調方案(Izacard et al., 2022)。相較于微調模型需要重新訓練參數的方式,RAG 技術通過動態檢索外部知識庫實現行業適配,無需承擔高昂的模型重訓練成本。
2.2 部署方式:完全本地部署
通過全鏈路本地化部署架構,實現數據從存儲到處理的端到端閉環,在消除外部攻擊面的同時確保毫秒級響應速度。技術驗證采用 Ollama 容器化框架集成 Cherry Studio 平臺及 RAGFlow 智能檢索系統,基于離線環境完成向量數據庫構建與模型推理,使敏感信息全程駐留內網。
2.3 實現效果:高效、準確、清晰
該 “虛擬工程師” demo 可以快速且準確地查詢 CST、ABAQUS 軟件的幫助文檔和工程案例,相比傳統檢索的方式, “虛擬工程師” demo 更能深刻理解用戶的需求。通過 DeepSeek-R1 模型與 RAG 技術的結合,“虛擬工程師” demo 能夠快速、準確地找到相關文檔和案例,提供精準的答案和建議。
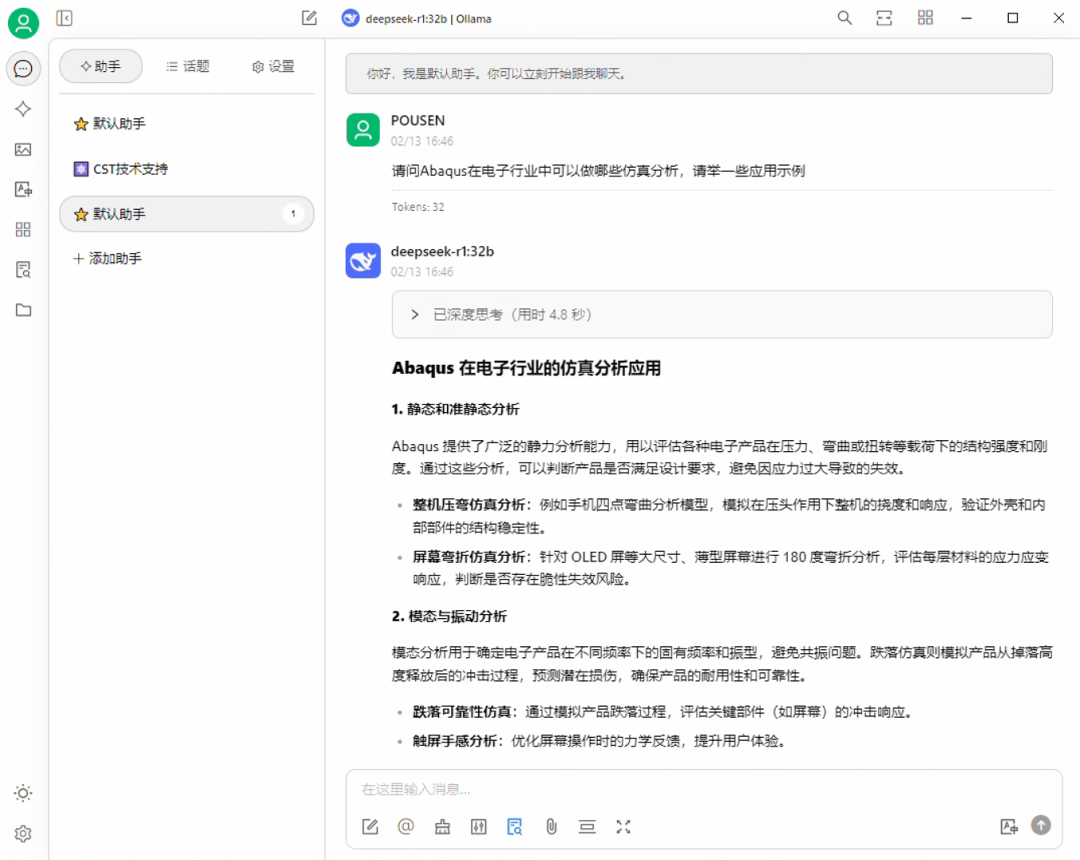
ABAQUS 問題響應結果
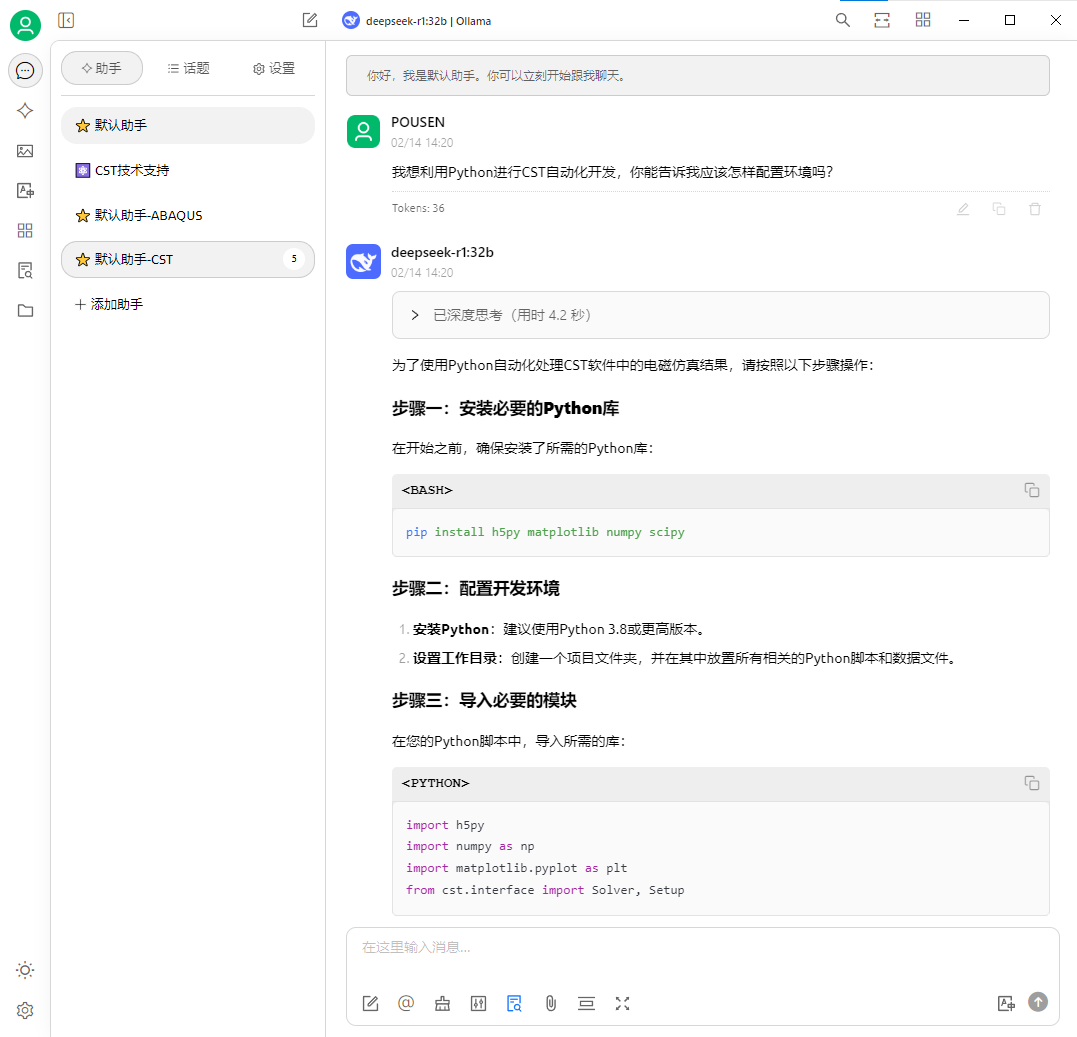
CST 問題響應結果
相比傳統的單純使用 “微調模型” 技術方案(可類比為 “考前復習”),大模型與 RAG 技術工作流程(可類比為 “開卷考試”)能夠結合具體行業學習的內容,更有針對性地給出建議的解決方案。該方案不僅提升了模型的適應性和靈活性,還顯著提高了問題解決的效率和準確性。
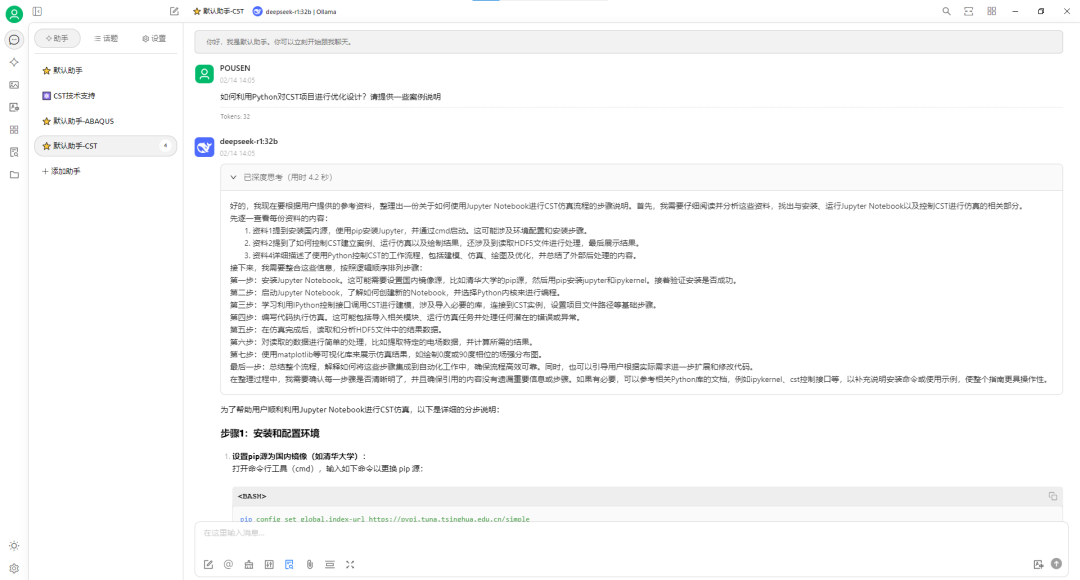
部署本地知識庫后,在思考的過程中會引用知識庫內容
三、部署流程
3.1 總覽
下表展示了不同部署方式的主要特點,大家可以根據自身的情況和需求,決定部署的方式。
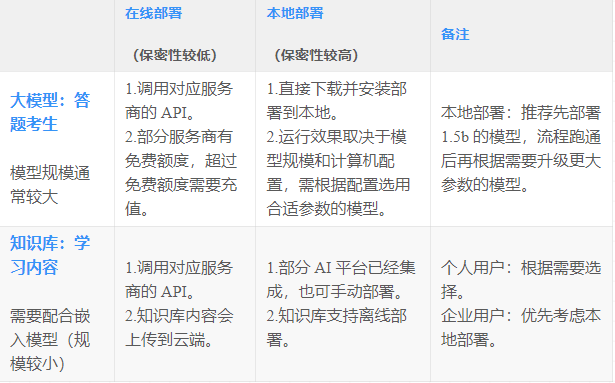
本文將聚焦本地化部署方案,以輕量級模型DeepSeek-R1:1.5b為示范,通過三步走流程實現零門檻安裝:
環境搭建:使用開源工具Ollama,通過 ollama run deepseek-r1:1.5b 命令完成模型加載;
離線運行:所有數據在本地完成向量化處理與推理,避免敏感信息外傳;
硬件適配:1.5b 版本僅需 4GB 內存即可流暢運行,適合個人電腦部署。
3.2 部署DeepSeek
1、從官網下載并安裝Ollama,過程略。可參考 https://ollama.com/
點擊 Download 下載對應系統版本的安裝包。
2、在 Ollama 模型列表中復制命令ollama run deepseek-r1:1.5b,粘貼到命令行中,等待下載完成。
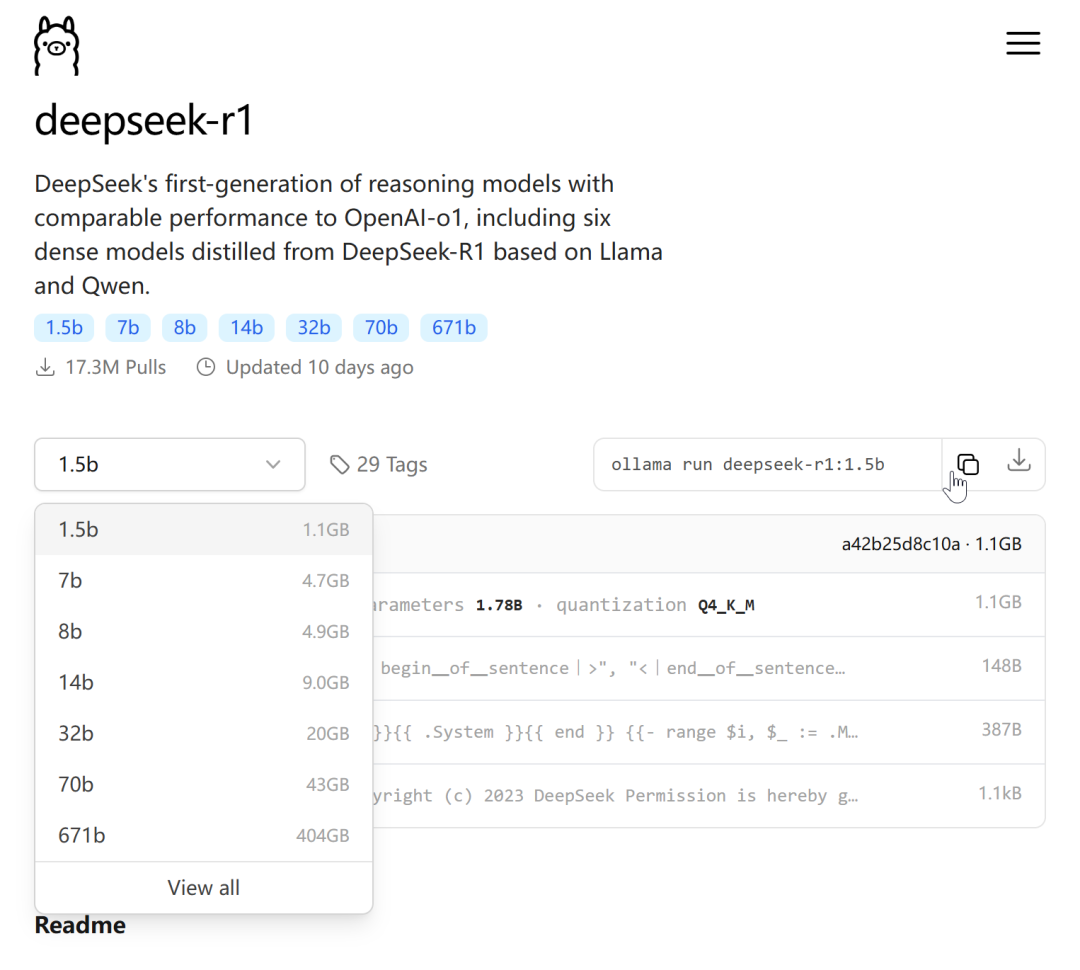
此處以最低版本作為示例,后續會推薦適合的模型規模。
?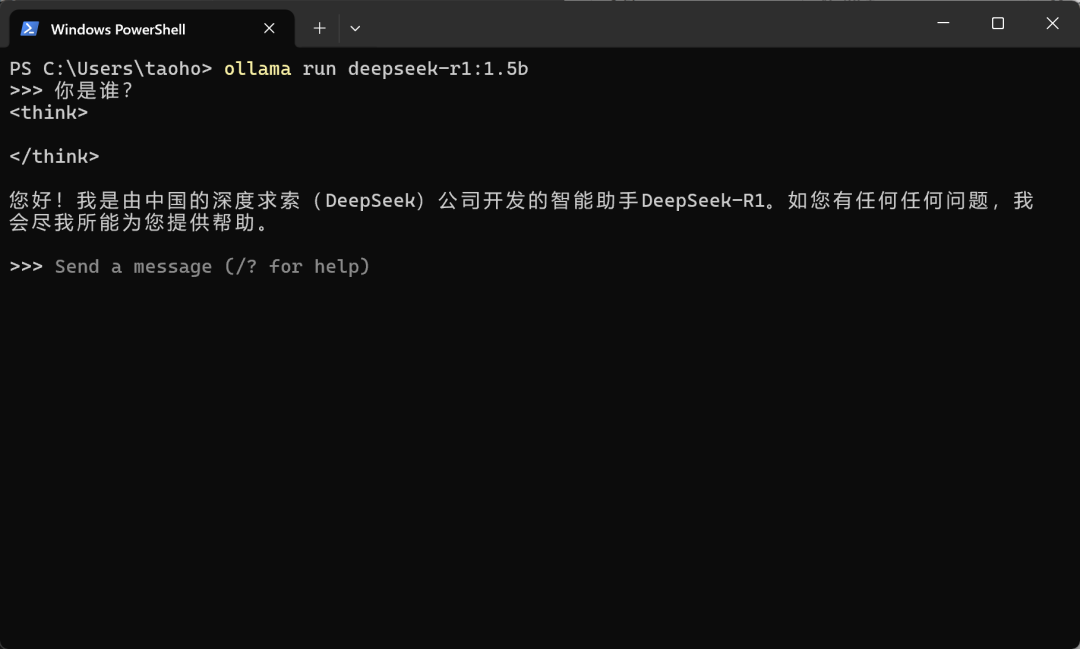
下載完成后,可直接在命令行中與模型對話,檢查模型能否正常加載。
3、安裝對話界面軟件,可以更直觀地調整模型的參數和提示詞,同時也支持將對話內容完全存檔在本地。推薦Cherry Studio https://cherry-ai.com/
4、配置遠程 Ollama 服務(可選)。默認情況下,Ollama 服務僅在本地運行,不對外提供服務。要使 Ollama 服務能夠覆蓋在局域網內的設備中,需要設置以下兩個環境變量:
OLLAMA_HOST=0.0.0.0
OLLAMA_ORIGINS=*
5、評估電腦最大可以運行的模型參數。根據對應參數的模型大小,對比計算機配置(如顯卡、顯存、內存、CPU等)與實際應用效果(如共享顯存占用、CPU/GPU占用等)。
3.3 知識庫
簡略版:使用內置知識庫的 AI 對話平臺
以下平臺可根據個人喜好選擇:
1.Cherry Studio設置方式:參考 https://docs.cherry-ai.com/knowledge-base/knowledge-base
2.AnythingLLM設置方式:參考 https://docs.anythingllm.com/introduction
至尊版:使用 docker 部署 RAGFlow
可參考:
https://ragflow.io/
https://www.bilibili.com/video/BV1WiP2ezE5a/
1.安裝 RAGFlow 1. 安裝 docker 2. 拉取 RAGFlow 鏡像
可訪問官方 GitHub 倉庫的 README 頁面拉取鏡像,并按照文檔中的指引安裝部署:https://github.com/infiniflow/ragflow/blob/main/README_zh.md
如果遇到問題,可訪問網絡上部署 RAGFlow 的踩坑帖子,如:https://blog.csdn.net/gr1785/article/details/145543754?spm=1001.2014.3001.5502
2.添加本地模型
1、在瀏覽器輸入http://localhost:88,并注冊賬號和組織(該賬號基于本地服務)。
2、在頁面中選擇 Ollama,并選擇對應的模型類型。(DeepSeek 模型選擇 chat,bge-m3 模型選擇 embedding)
3、按照控制臺Ollama -list命令中列出的模型名稱填寫(建議在列表中復制)。
4、基礎 URL:http://host.docker.internal:11434
5、最大 token 數可隨便填寫(本地部署不消耗在線
token)。
6、按照上述方法分別添加 chat 模型和 embedding 模型。
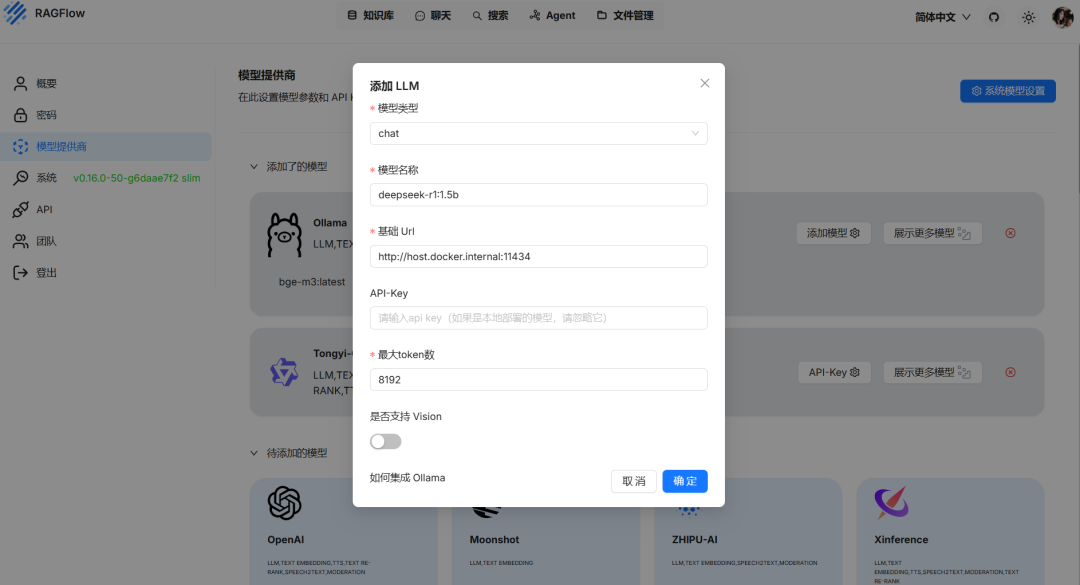
RAGFlow 添加本地模型配置示例
3、設置快速啟用服務腳本
可編寫一個批處理文件start_ragflow.bat
@echo off
:: 解決中文亂碼問題
chcp 65001 >nul
title RAGFlow啟動器
:: 進入docker目錄啟動服務
cd /d "你的RAGFlow路徑,以\ragflow-main\docker結尾"
docker compose up -d
:: 打開瀏覽器訪問頁面
start """http://localhost:80"
echo RAGFlow服務已啟動,瀏覽器即將打開...
pause `
4、設置知識庫
由于網上關于RAGFlow的內容眾多,在 RAGFlow 中設置知識庫的具體步驟,可根據官方文檔或網絡教程操作,在此不再贅述。
創建好的知識庫
3.4 參數調整
參數背景知識
Temperature(溫度) :
溫度參數控制模型生成文本的隨機性和創造性程度(默認值為0.7或1.0,不同軟件/平臺有不同的設置)。具體表現為:
低溫度值(0-0.3):輸出更確定、更專注,適合代碼生成、數據分析等需要準確性的場景。
中等溫度值(0.4-0.7):平衡了創造性和連貫性,適合日常對話、一般性寫作。
高溫度值(0.8-1.0):產生更具創造性和多樣性的輸出,適合創意寫作、頭腦風暴等場景。
Top P(核采樣):
默認值為 1,值越小,AI 生成的內容越單調,也越容易理解;值越大,AI 回復的詞匯范圍越大,越多樣化。
核采樣通過控制詞匯選擇的概率閾值來影響輸出:
較小值(0.1-0.3):僅考慮最高概率的詞匯,輸出更保守、更可控,適合代碼注釋、技術文檔等場景。
中等值(0.4-0.6):平衡詞匯多樣性和準確性,適合一般對話和寫作任務,
較大值(0.7-1.0):考慮更廣泛的詞匯選擇,產生更豐富多樣的內容,適合創意寫作等需要多樣化表達的場景。
??
場景配置
不同業務場景中 LLM 模型的參數需求往往有著明顯差異,需要結合理論與實踐結果進行調整。下表系統地梳理了Temperature與Top-P參數的協同配置策略,綜合考量了輸出質量、創意需求及風險控制三個維度,并標注典型應用場景的實踐驗證效果。
| 場景 | Temperature 范圍 | Top-P 范圍 | 說明 |
|---|
| 代碼生成 | 0.1–0.3 | 0.1–0.3 | 極低溫+極低Top-P,減少語法錯誤,確保代碼邏輯正確。 |
| 技術文檔如代碼、產品說明 | 0.2–0.5 | 0.5–0.7 | 低溫+中低Top-P,確保輸出準確結構化,避免冗余內容。 |
| 客戶服務如聊天機器人 | 0.5–0.8 | 0.7–0.9 | 平衡自然與可控,保留部分多樣性以靈活應答。 |
| 創意寫作如詩歌、故事生成 | 0.7–1.2 | 0.8–0.95 | 高溫+高Top-P,鼓勵多樣性,需注意邏輯連貫性。 |
| 開放探索如頭腦風暴、靈感激發 | 1.0–1.5 | 0.95–1.0 | 高溫+全覆蓋Top-P,犧牲準確性以激發意外創新。 |
| 本地知識庫如業務數據分類、結構化信息抽取、知識問答 | 0.2–0.5 | 0.5–0.7 | 降低隨機性,確保輸出穩定和事實準確,同時聚焦高頻候選詞,避免低質量內容干擾。 |
參數調整建議
優先調整單一參數:通常僅需調整Temperature或Top-P,避免兩者同時大幅改動。
高溫+中低Top-P:在創意任務中,高溫配合稍低Top-P(如0.8)可平衡多樣性與質量。
低溫+低Top-P:用于高精度任務(如法律文本生成),確保輸出高度可控。
提示詞約束: 可以增加知識庫中無查詢內容情況下輸出信息,最大化利用模型本身的知識范圍。例如:【如果知識庫中沒有找到相關的信息,請現在回答的開頭說明“我不了解這個問題,但我會根據我自己的理解嘗試回答”,然后再討論你的見解。】
四、總結
通過以上操作,即可在本地計算機或服務器上搭建一套完全離線的 AI 本地知識庫查詢系統。且效果能夠隨著模型參數、知識庫參數的優化而變得更明顯。目前,該方案已在企業內部知識管理、智能客服等場景落地,在保障數據安全的前提下,讓企業知識庫真正「活起來」。
DeepSeek 推理模型與 RAG 技術的結合,為構建企業專屬知識庫的業務場景提供了高效的解決方案。通過將行業積累的技術文檔、項目經驗等結構化數據與 AI 深度結合,既能讓系統精準理解專業術語,又能基于實時更新的知識庫生成可靠回答。采用這種架構的方案,既保留了通用大模型的對話能力,又通過持續學習企業特有知識,實現「越用越懂業務」的個性化效果。
該文章在 2025/3/11 18:11:39 編輯過






 400 186 1886
400 186 1886


