[點晴CRM客戶管理系統]簡單分析搜索引擎蜘蛛的爬取策略
當前位置:點晴教程→點晴CRM客戶管理信息系統
→『 經驗分享&問題答疑 』
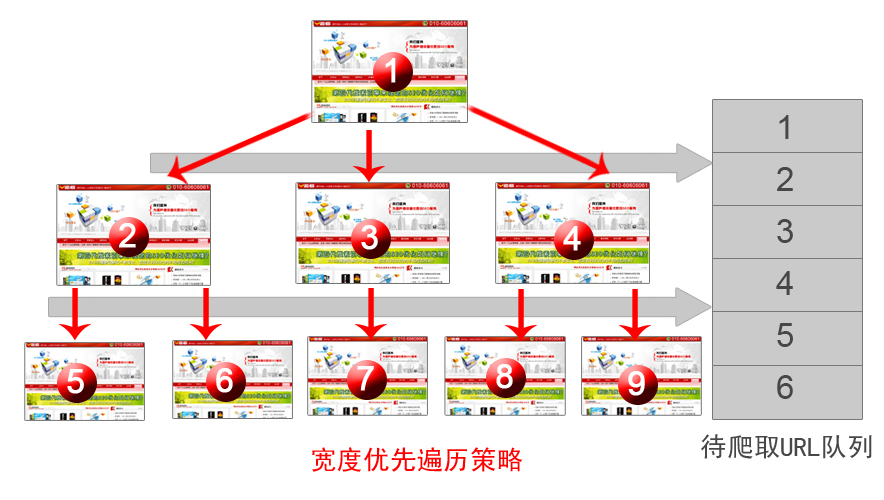
搜索引擎蜘蛛每天是怎么樣去爬取我們的網的呢?針對這些你有多少的了解?那搜索引擎蜘蛛的爬取過程又是怎么樣的呢?在搜索引擎蜘蛛系統中,待爬取URL隊列是很關鍵的部分,需要蜘蛛爬取的網頁URL在其中順序排列,形成一個隊列結構,調度程序每次從隊列頭取出某個URL,發送給網頁下載器頁面內容,每個新下載的頁面包含的URL會追加到待爬取URL隊列的末尾,如此形成循環,整個爬蟲系統可以說是由這個隊列驅動運轉的。同樣我們的網站每天都要經過這樣一個隊列,讓搜索引擎進行爬取的。 那么待爬取URL隊列中的頁面URL 的排列順序是如何來確定的呢?上面我們說了將新下載頁面中的包含的鏈接追加到隊列尾部,這固然是一種確定隊列URL順序的方法,但并非唯一的手段,事實上,還可以采納很多其他技術來實現,將隊列中待爬取的URL進行排序。那么究竟搜索引擎蜘蛛是按照什么樣的策略進行的爬取呢?以下我們來進行更深入的分析吧。 第一、寬度優化遍歷策略 寬度優化遍歷是一種非常簡單直觀且歷史很悠久的遍歷方法,在搜索引擎爬蟲一出現就開始采用了。新提出的抓取策略往往會將這種方法作為比較基準,但應該注意到的是,這種策略也是一種相當強悍的方法,很多新方法實際效果不見昨比寬度優化遍歷策略好,所以至今這種方法也是很多實際爬蟲系統優先采用的爬取策略。網頁爬取順序基本是按照網頁的重要性排序的。之所以如此,有研究人員認為,如果某個網頁包含很多入鏈,那么更有可能被寬度優化遍歷策略早早爬到,而入鏈這個數從側面體現了網頁的重要性,即實際上寬度優化遍歷策略隱含了一些網頁優化級假設。
第二、非完全pagerank策略 PageRank是一種著名的鏈接分析算法,可以用來衡量網頁的重要性。很自然地,可以想到用PageRank的思想來對URL優化級進行排序。但是這里有個問題,PageRank是個全局性算法,也就是說當所有網頁下載完成后,其計算結果才是可靠的,而爬蟲的目的就是去下載網頁,在運行過程中只能看到一部分頁面,所以在爬取階段的網頁是無法獲得可靠的PageRank得分的。對于已經下載的網頁,加上待爬取的URL隊列中的一URL一起,形成網頁集合,在此集合內進行PageRank計算,計算完成之后,將待爬取URL隊列里的網頁按照按照PageRank得分由高低排序,形成的序列就是爬蟲接下來應該依次爬取的URL列表。這也是為何稱之為“非完全PageRank”的原因,。 第三、OPIC策略( Online Page Importance Computation) OPIC的字面含義是“在線頁面重要性計算”,可以將其看做是一種改進的PageRank算法。在算法開始之前,每個互聯網頁面都給予相同的現金,每當下載了某個頁面P后,P就將自己擁有的現金平均分配給頁面中包含的鏈接頁面,氫自己的現金清空。而對于待爬取URL隊列中的網頁,則根據其手頭擁有的現金金額多少排序,優先下載現金最充裕的網頁,OPIC從大的框架上與PageRank思路基本一致,區別在于:PageRank每次需要迭代計算,而OPIC策略不需要迭代過程。所以計算速度遠遠快與PageRank,適合實時 計算使用。同時,PageRank,在計算時,存在向無鏈接關系網頁的遠程跳轉過程,而OPIC沒有這一計算因子。實驗結果表明,OPIC是較好的重要性衡量策略,效果略優于寬度優化遍歷策略。 第四、大站優化策略 大部優化策略思路很直接:以網站為單位來選題網頁重要性,對于待爬取URL隊列中的網頁根據所屬網站歸類,如果哪個網站等待下載的頁面最多,則優化先下載這些鏈接,其本質思想傾向于優先下載大型網站。因為大型網站往往包含更多的頁面。鑒于大型網站往往是著名企業的內容,其網頁質量一般較高,所以這個思路雖然簡單,但是有一定依據。實驗表明這個算法效果也要略優先于寬度優先遍歷策略。 第五、網頁更新策略 互聯網的動態是其顯著特征,隨時都有新出現的頁面,頁面的內容被更改或者本來存在的頁面刪除。對于爬蟲來說,并非將網頁抓取到本地就算完成任務,也要體現出互聯網這種動態性。本地下載的網頁可被看做是互聯網頁的鏡像,爬蟲要盡可能保證其一致性。可以假設一種情況:某 個網頁已被刪除或者內容做出重大變動,而搜索引擎對此惘然無知,仍然按其舊有內容排序,將其作為搜索結果提供給用記,其用戶體驗度之糟糕不言而喻。所以對于已經爬取的網頁,爬蟲還要負責保持其內容和互聯網頁面內容的同步,這取決于爬蟲所彩用的網頁更新策略。網頁更新策略的任務是要決定何時重新爬取之前已經下載過和網頁,以盡可能使得本地下載網頁和互聯網原始頁面內容保持一致。常用的網頁更新策略有三種:歷史參考策略,用戶體驗度策略和聚類抽樣策略。 (1)什么是歷史參考策略? 歷史參考策略是最直觀的一種更新策略,它建立于如下假設之上:過去頻繁更新的網頁,那么將來也會頻繁更新,所以為了預估某個網頁何時進行更新,可以通過參考其歷史更新情況來做出決定。 從這一點可以看出,我們網站的更新一定要有規律的進行,這樣才能讓搜索引擎蜘蛛更好的來關注你的網站,把握你的網站,很多人在更新網站的時候,不知道為什么要做規律性的更新,這就是真正存在的原因。 (2)什么是用戶體驗度策略? 這個很明顯,大家都知道。一般來說,搜索引擎用戶提交查詢結果后,相關的搜索結果可能成千上萬,而用戶沒有耐心去查看排在后面的搜索結果,往往只盾前三頁搜索內容,用戶體驗策略就是利用搜索引擎用戶的這個特點來設計更新策略的。 (3)聚類抽樣策略 上面介紹的兩種網頁更新策略嚴重依賴網頁的歷史更新信息,因為這是能夠進行后續計算的基礎。但在現實中為每個網頁保存歷史信息,搜索系統會增加 額外的負擔。從另外一個角度考慮,如果是首次爬取的網頁,因為沒有歷史信息,所以也就無法按照這兩種思路去預估其更新周期,聚類抽樣,策略即是為了解決上述缺點而提出的。網頁一般具有一些屬性,根據這些屬性可以預測其更新周期,具有相信屬性的網頁,其更新周期也是類似的。 通過以上對搜索引擎蜘蛛的爬取過程以及爬取策略進行了簡單的了解之后,你是否應該有些考慮了?試著對自己的網站進行改變了?以上的一些原因說明了搜索引擎的更新是有規律以及有章法進行的,要想更能適應搜索引擎的更新原則和蜘蛛爬取原則,我們就應該從更基礎的入手去進行全面的分析和總結。 該文章在 2013/3/27 22:24:58 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886